In this fourth installment of the framework series, we will add a T-SQL batching feature to our existing framework we have developed in earlier installments of this series. This feature set is dependent on the work we have previously, done. If you have not been following along, please go back so that everything will work as anticipated (part 1, part 2, part 3).
There are no boundaries to what you can add to this or your own framework. I have chosen these three features (error log, activity log, batching) so I could illustrate examples. The possibilities are limitless, hindered only by your imagination. This next feature is multi-faceted, but we will focus on just the idea of T-SQL batching procedure calls to further extend logging.
We could develop this feature more to include batching of rows, batching parent and child structures so that segregation of domain aspects of the data model are defined, batching of similar lines of business… In short, we could develop batching out to almost any type of grouping one would need programmatically to have data-driven processes leveraged within the framework.
Creating T-SQL Batching: First Steps
As stated above, we will focus on developing the batching feature to extend the logging and information needed when we execute stored procedures as part of the framework. Even though we are focused on just this aspect of the feature, we will develop it in a way that it will scale if one would want to extend the feature’s functionality, which I will point out as we develop. There are a couple of moving parts for this feature (especially since we want it to easily expand in the future), so this will be a longer post. We will keep it easy to consume just as we have done with earlier posts.
Since we have some moving parts, let’s create a basic outline of precedence so that we follow the checklist as we develop. I highly recommend you take the time on any new project to get your thoughts down and have a road map with a clear vision of what you want to end up with as a solution.
- Create the Batch table (this is kind of like a header table)
- Create the batch detail table
- Add a “Batching” type code to our code group and code tables
- Create a scalar function to create new IDs for the Batch table
- Create the Insert/Update (DLL) procedures for the batching feature
- Update the Template (there will be some logic also involved past just proc calls)
- Remove all data from the Error log/Activity Log/Batching Tables
- Create a demo to test and validate our features
- Review the results
- Do a happy dance as customary when any development project is complete
Scale: Planning for the Future
There is a lot to do in developing this feature. The hard part is already done — we have defined above exactly what we need to do. Now we just need to create simple processes to complete each stage independently, and add the completed tasks to the collection like a puzzle until we are done … it really is that simple.
Since we may extend this feature in the future, we should allow for scalability, especially as we create the structures that will hold the data for this feature. Let’s explore what we envision this feature to do for us in the framework. We have an error handler, and we have a system for logging the details about every stored procedure we create and execute. Now we are developing a system that will group stored procedures that are nested, and define the details of this group like:
- What stored procedure started the chain of procedures being executed?
- How long did each segment of the batch (or each procedure) take?
- How long did the entire batch take?
- Did all procedures in the batch execute successfully?
- Which procedure (if any) did not complete successfully?
Some of the information gathered could be construed from other aspects of the framework. For example, what procedure did not execute successfully … we could find this easily from the activity log or even the error log. However, when you are looking at a specific process (especially a complicated process), looking for individual records that may or may not be affecting the process would not be as efficient as if you were looking at the stored procedures that specifically were called by the known process as a group.
Creating the Batch Table
The features we are creating also complement each other. In the last blog we observed that the work we developed in the error handling feature set was used in the activity log to enhance the logging capability of the activity log. Here, you’ll see that we leverage the features developed in the activity log to enhance the logging of the T-SQL batching process.
At this point we should have a pretty clear vision as to what we expect from our feature set; we have a clear road map to follow; and we have a lot of work to do so let’s get started!
The first task is to create the Batch table, which if you will remember constitutes as a header, so to speak, as listed below:



/*=======================================================================*/
/****** Object: Table [dbo].[TU_Batch] Script Date: 2019-08-21 ******/
/*=======================================================================*/
PRINT CHAR(10) + CHAR(13) + 'Creating table [dbo].[TU_Batch].';
CREATE TABLE [dbo].[TU_Batch]
(
[Batch_ID] [UNIQUEIDENTIFIER] NOT NULL
CONSTRAINT [PK_Batch_ID]
PRIMARY KEY CLUSTERED
CONSTRAINT [DF_Batch_ID]
DEFAULT CONVERT(UNIQUEIDENTIFIER, CONVERT(BINARY(10), NEWID()) +
CONVERT(BINARY(6), GETDATE()))
,[Type_ID] [INT] NOT NULL
CONSTRAINT [FK_TU_Batch_Type_ID]
FOREIGN KEY ([Type_ID])
REFERENCES [TU_Code]([Code_ID])
CONSTRAINT [DF_TU_Batch_Type_ID]
DEFAULT 0
,[Name] [NVARCHAR](100) NOT NULL
CONSTRAINT [DF_TU_Batch_Name]
DEFAULT 'Batch:' + CONVERT(NVARCHAR(10), GETDATE(), 110)
,[Parent_ID] [INT] NULL
,[Active] [BIT] NOT NULL
CONSTRAINT [DF_TU_Batch_Active]
DEFAULT 1
,[DateCreated] [DATETIME] NOT NULL
CONSTRAINT [DF_TU_Batch_DateCreated]
DEFAULT GETDATE()
,[DateModified] [DATETIME] NOT NULL
CONSTRAINT [DF_TU_Batch_DateModified]
DEFAULT GETDATE()
) ON [PRIMARY];
/* FK Index */
CREATE NONCLUSTERED INDEX idxfk_TU_Batch_Type_ID ON [TU_Batch]([Type_ID])The Benefits of GUIDS
Before we continue, let’s look at our first column here: the batch_id that we have set as a uniqueidentifier. We also need to discuss the default that converts in and out of binary. Why would we go down this road if we are trying to keep things as simple as we can? There is no good reason for the feature set we are developing today, but we are building this feature set to scale. To this end we have some very good reasons as to why we want a uniqueidentifier:
- If and when we extend our batching feature, this feature may need to extend past processing in the database (or server for that matter), or origin. We can do batching through SSIS on a completely different server, so we should set the feature to be federated. Since identity uses integers that do not extend past the source database, the GUID is a practical data type that can be validated across the domain and even beyond.
- This is not an application, so we control creation and storage of the GUIDS. The GUIDS reads from right to left, so if we concatenate the random unique identifier with a time stamp on the end, we will have a sequential GUID that will not cause sporadic inserts across our extents.
- For future needs, we may want to copy a batch for reuse. Validating a copied GUID may be easier to identify than integers when not done programmatically.
[Batch_ID] [UNIQUEIDENTIFIER] NOT NULL
CONSTRAINT [PK_Batch_ID]
PRIMARY KEY CLUSTERED
CONSTRAINT [DF_Batch_ID]
DEFAULT CONVERT(UNIQUEIDENTIFIER, CONVERT(BINARY(10), NEWID()) +
CONVERT(BINARY(6), GETDATE()))Digging Deeper
This type of method is starting to go beyond level 1 development. Now that we have defined why you will see that, it is convenient to apply this type development to the feature we are building out. We started explaining the DEFAULT argument above in the second article of why we want a GUID, but as this is important, let’s expand on this before we move on:
- A GUID is 16 alpha-numeric characters read from right to left
- The NEWID() Function is a server-side function that randomly creates a new 16-character UNIQUIDENTIFIER (nicknamed: GUID)
- The GETDATE() Function is a server-side function that returns a date
- We use the Binary datatype to concatenate the first 10 characters of the NEWD() with the first six characters of a sorted date — CONVERT(BINARY(10), NEWID()) + CONVERT(BINARY(6), GETDATE())
- Then we convert that to a UNIQUIDENTIFIER —
CONVERT(
UNIQUEIDENTIFIER,
CONVERT(BINARY(10), NEWID()) + CONVERT(BINARY(6), GETDATE())
)
Create Batch Detail Table
Next, we’ll create the batch detail table, shown below:
/*=========================================================================*/
/****** Object: Table [dbo].[TU_BatchDetail] Script Date: 2019-05-24 **/
/*=========================================================================*/
PRINT CHAR(10) + CHAR(13) + 'Creating table [dbo].[TU_BatchDetail].';
CREATE TABLE [dbo].[TU_BatchDetail]
(
[BatchDetail_ID] [INT] IDENTITY (1, 1) NOT NULL
CONSTRAINT [PK_BatchDetail_ID]
PRIMARY KEY CLUSTERED
,[Batch_ID] [UNIQUEIDENTIFIER] NOT NULL
CONSTRAINT [FK_TU_BatchDetail_Batch_ID]
FOREIGN KEY ([Batch_ID])
REFERENCES [TU_Batch]([Batch_ID])
,[BatchSize] [INT] NOT NULL
CONSTRAINT [DF_TU_Batch_BatchSize]
DEFAULT 0
,[OBJECT_ID] [INT] NULL
,[Entity_ID] [UNIQUEIDENTIFIER] NULL
,[OBJECT] [NVARCHAR](100) COLLATE SQL_Latin1_General_CP1_CI_AS NULL
,[StartDate] [DATETIME] NULL
,[EndDate] [DATETIME] NULL
,[Rank] [INT] NOT NULL
CONSTRAINT [DF_TU_BatchDetail_Rank]
DEFAULT 1
,[Active] [BIT] NOT NULL
CONSTRAINT [DF_TU_BatchDetail_Active]
DEFAULT 1
,[DateCreated] [DATETIME] NOT NULL
CONSTRAINT [DF_TU_BatchDetail_DateCreated]
DEFAULT GETDATE()
,[DateModified] [DATETIME] NOT NULL
CONSTRAINT [DF_TU_BatchDetail_DateModified]
DEFAULT GETDATE()
) ON [PRIMARY];
/* FK Index */
CREATE NONCLUSTERED INDEX idxfk_TU_BatchDetail_Batch_ID ON [TU_BatchDetail]([Batch_ID])
This table is pretty standard, other than we put a couple of columns in that we will not need for this part of the feature, such as the batch size, which we would use to record size batches. That doesn’t mean this table won’t need modification when one decides to extend the batching features. But as you can see, we’re close enough that development could continue if desired.
Code Group and Code Tables
We’ve completed the first two items in our road map. Now we need to insert the type codes into our code group and code tables accordingly. In the second part of the framework, we created the Code Group and Code tables so that when we needed new codes we would not have to create new tables. Here we need new codes. We developed a great structure already so we can skip table creation because the structures we need are already available.
Let’s do this one at a time starting with the TU_CodeGroup table.
- Look at what’s in the table currently:

- We see there is only one record for the Error handling feature, so let’s insert a record for batching:
SET IDENTITY_INSERT TU_CodeGroup ON;
INSERT [DBCATCH].[dbo].[TU_CodeGroup]
( CodeGroup_ID, Name, [DESC])
SELECT 2, 'BATCH', 'TYPE OF BATCHS'
SET IDENTITY_INSERT TU_CodeGroup OFF;- Check the table again:
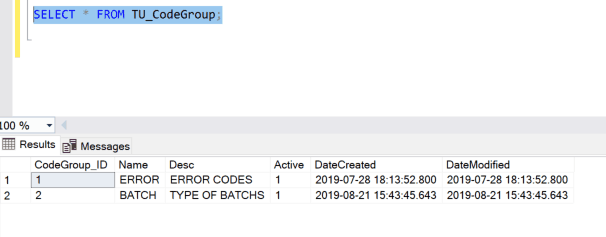
Exactly what we were anticipating. Follow the same three steps and insert the codes into the code table for the batching types:
- Look at what is in the table currently:

- After looking at the data we insert the data we need for batching:
SET IDENTITY_INSERT TU_Code ON;
INSERT [DBCATCH].[dbo].[TU_Code]
Code_ID, CodeGroup_ID, Name, [DESC])
SELECT 200, 2, 'DEFAULT', 'DEFAULT BATCH TYPE'
UNION
SELECT 201, 2, 'PROCEDURE', 'SP BATCH FOR ORDINAL COLLECTION'
UNION
SELECT 202, 2, 'RECORDCOUNT', 'SET NUMBER OF RECORDS TO be BATCHED'
SET IDENTITY_INSERT TU_Code OFF;- Check the code tables again:

The Scalar Function
Now that we have successfully entered our type codes, we move forward to creating a scalar function. This function does exactly as planned with the table definition: it will get a new uniqueidentifier for us.
We do this through a scalar function. It’s easier to create one into a variable and use that through nested operation versus a lookup each time. If we use a scalar function each time, why go to the trouble of creating a default in the table definition? That’s for completeness and for our protection. Instead of erroring out of a process, if a null is ever passed it will get an ID and allow the process to continue. With that, here’s the code for the scalar function as we continue our development:
USE [DBCATCH];
GO
IF EXISTS(SELECT 1
FROM [INFORMATION_SCHEMA].[ROUTINES] (NOLOCK)
WHERE [SPECIFIC_SCHEMA] = 'dbo'
AND [SPECIFIC_NAME] = 'FSU_GetGUID')
BEGIN
DROP FUNCTION [dbo].[FSU_GetGUID];
PRINT '<<< DROPPED FUNCTION [dbo].[FSU_GetGUID] >>>';
END;
GO
CREATE FUNCTION [dbo].[FSU_GetGUID]
(
@p_Guid [UNIQUEIDENTIFIER]
,@p_Date [DATETIME]
)
RETURNS [UNIQUEIDENTIFIER]
WITH ENCRYPTION
AS
BEGIN -- Begin function
/************************************************************************/
/* Name : FSU_GetGUID */
/* Version : 1.0 */
/* Author : Jared Kirkpatrick */
/* Date : 2019-08-24 */
/* Description : Gets a new binary sorted guid */
/************************************************************************/
/* Date : Version: Who: Description */
/************************************************************************/
/* 2019-08-24 : 1.0 : JSK: Initial Release. */
/************************************************************************/
/* Declare Variables */
DECLARE @v_GUID [UNIQUEIDENTIFIER];
SELECT @v_GUID = CONVERT(UNIQUEIDENTIFIER,
CONVERT(BINARY(10), @p_Guid) +
CONVERT(BINARY(6), @p_Date)
)
RETURN @v_GUID
END; -- Begin function
GO
IF OBJECT_ID('[dbo].[FSU_GetGUID]') IS NOT NULL
BEGIN
PRINT '<<< CREATED FUNCTION [dbo].[FSU_GetGUID] >>>';
END;
ELSE
BEGIN
PRINT '<<< FAILED TO CREATE FUNCTION [dbo].[FSU_GetGUID] >>>';
END;
GOCreating the Procedures
Next on the list is to create the Insert/Update procedures for the Batch and Batch Detail tables. We should not have any reason to modify the header records. The Batch table will only need an Insert procedure, whereas the Detail tables will need both an Insert and an update procedure.
USE DBCATCH
GO
IF EXISTS(SELECT 1
FROM [dbo].[sysobjects] (NOLOCK)
WHERE [id] = OBJECT_ID(N'[dbo].[PU_Batch_ADD]')
AND OBJECTPROPERTY([id], N'IsProcedure') = 1)
BEGIN
DROP PROCEDURE [dbo].[PU_Batch_ADD];
PRINT '<<< DROPPED PROCEDURE [dbo].[PU_Batch_ADD] >>>';
END
GO
CREATE PROC [dbo].[PU_Batch_ADD]
@p_Type_ID [INT] = 700,
@p_Name [NVARCHAR](100) = NULL,
@p_Parent_ID [INT] = NULL,
@p_Batch_ID [UNIQUEIDENTIFIER] = NULL OUTPUT
WITH ENCRYPTION
AS
/*************************************************************************************************/
/* Name : PU_Batch_ADD */
/* Version : 1.0 */
/* Author : Jared Kirkpatrick */
/* Date : 2019-08-24 */
/* Description : Insertes a record in the Batch Header */
/*************************************************************************************************/
/* Date : Version: Who: Description */
/*************************************************************************************************/
/* 2019-08-24 : 1.0 : REB: Initial Release. */
/*************************************************************************************************/
SET NOCOUNT ON;
/* Declare Variables */
DECLARE @v_Now [DATETIME]
,@v_Domain [NVARCHAR](100)
,@v_IPAddress [NVARCHAR](100)
,@v_SQL [NVARCHAR](4000)
,@v_UserName [NVARCHAR](100)
,@v_PW [NVARCHAR](100)
,@v_Error [INT]
,@v_ActivityLog_ID [INT]
,@v_DB [NVARCHAR](100)
,@v_Obj [NVARCHAR](100)
,@v_App [NVARCHAR](100)
,@v_User [NVARCHAR](100)
,@v_Spid [NVARCHAR](100)
,@v_Debug [BIT]
,@v_MSG [NVARCHAR](1000)
,@v_SystemName [NVARCHAR](100)
,@v_Connect_Type_ID [INT]
,@v_RowCount [INT]
,@v_Count [INT]
,@v_Version [INT]
,@v_MSSQL_ID [INT];
/* Define Variables */
SELECT @v_Now = GETDATE()
,@v_DB = DB_NAME()
,@v_Obj = '[DBCATCH].[dbo].[PU_Batch_ADD]'
,@v_App = APP_NAME()
,@v_User = ISNULL(ORIGINAL_LOGIN(), USER_NAME())
,@v_Spid = CONVERT([NVARCHAR](25), @@SPID)
,@v_Debug = 0;
IF @p_Name IS NULL
BEGIN
SELECT @p_Name = 'Batch:' + CONVERT(NVARCHAR(10), @v_Now, 112);
END;
IF @p_Batch_ID IS NULL
BEGIN
SELECT @p_Batch_ID = CONVERT(UNIQUEIDENTIFIER, CONVERT(BINARY(10), NEWID()) +
CONVERT(BINARY(6), GETDATE()));
END;
IF @v_Debug = 1
BEGIN -- debug = 1 Ref: 1
SELECT 'REF:1 - Define Static Variables';
SELECT @v_Now AS [GETDATE]
,@v_DB AS [DB]
,@v_Obj AS [OBJ]
,@v_App AS [APP]
,@v_User AS [USER]
,@v_Spid AS [SPID]
,@p_Batch_ID AS [Batch_ID];
END; -- debug = 1
BEGIN TRANSACTION
BEGIN TRY
INSERT [DBCATCH].[dbo].[TU_Batch]
(
[Batch_ID],
[Type_ID],
[Name],
[Parent_ID]
)
VALUES
(
@p_Batch_ID,
@p_Type_ID,
@p_Name,
@p_Parent_ID
)
END TRY
BEGIN CATCH
SELECT @v_Error = 100001
,@v_MSG = CONVERT(NVARCHAR(2500),
'Error: ' + CONVERT([NVARCHAR](255), ISNULL(ERROR_NUMBER(), -1)) +
' Severity: ' + CONVERT([NVARCHAR](255), ISNULL(ERROR_SEVERITY(), -1)) +
' State: ' + CONVERT([NVARCHAR](255), ISNULL(ERROR_STATE(), -1)) +
' Line: ' + CONVERT([NVARCHAR](255), ISNULL(ERROR_LINE(), -1)) +
' Procedure: ' + CONVERT([NVARCHAR](255), ISNULL(ERROR_PROCEDURE(), @v_Obj)) +
' MSG: Error Inserting into [DBCATCH].[dbo].[TU_Batch] with error:' + ISNULL(ERROR_MESSAGE(), ''));
EXEC [DBCATCH].[dbo].[PU_ErrorLog_ADD]
@p_Error_ID = @v_Error,
@p_System = NULL,
@p_DB = @v_DB,
@p_Obj = @v_Obj,
@p_App = @v_App,
@p_User = @v_User,
@p_ErrorMsg = @v_MSG;
ROLLBACK TRAN;
RETURN @v_Error;
END CATCH;
COMMIT TRANSACTION;
GO
IF OBJECT_ID('[dbo].[PU_Batch_ADD]') IS NOT NULL
BEGIN
PRINT '<<< CREATED PROCEDURE [dbo].[PU_Batch_ADD] >>>';
END;
ELSE
BEGIN
PRINT '<<< FAILED TO CREATE PROCEDURE [dbo].[PU_Batch_ADD] >>>';
END;
GOThat takes care of the insert procedure for the Batch table. Notice we customized the TRY CATCH error message. The Insert Procedure for the Batch Detail record is below:
USE DBCATCH
GO
IF EXISTS(SELECT 1
FROM [dbo].[sysobjects] (NOLOCK)
WHERE [id] = OBJECT_ID(N'[dbo].[PU_BatchDetail_ADD]')
AND OBJECTPROPERTY([id], N'IsProcedure') = 1)
BEGIN
DROP PROCEDURE [dbo].[PU_BatchDetail_ADD];
PRINT '<<< DROPPED PROCEDURE [dbo].[PU_BatchDetail_ADD] >>>';
END;
GO
CREATE PROC [dbo].[PU_BatchDetail_ADD]
@p_Batch_ID [UNIQUEIDENTIFIER],
@p_BatchSize [INT] = 0,
@p_Object_ID [INT] = NULL,
@p_Entity_ID [UNIQUEIDENTIFIER] = NULL,
@p_Object [NVARCHAR](100) = NULL,
@p_StartDate [DATETIME] = NULL,
@p_EndDate [DATETIME] = NULL,
@p_Rank [INT] = NULL
WITH ENCRYPTION
AS
/*************************************************************************************************/
/* Name : PU_BatchDetail_ADD */
/* Version : 1.0 */
/* Author : Jared Kirkpatrick */
/* Date : 2019-08-24 */
/* Description : Inserts a record for the batch detail */
/*************************************************************************************************/
/* Date : Version: Who: Description */
/*************************************************************************************************/
/* 2019-08-24 : 1.0 : REB: Initial Release. */
/*************************************************************************************************/
SET NOCOUNT ON;
/* Declare Variables */
DECLARE @v_Now [DATETIME]
,@v_Domain [NVARCHAR](100)
,@v_IPAddress [NVARCHAR](100)
,@v_SQL [NVARCHAR](4000)
,@v_UserName [NVARCHAR](100)
,@v_PW [NVARCHAR](100)
,@v_Error [INT]
,@v_ActivityLog_ID [INT]
,@v_DB [NVARCHAR](100)
,@v_Obj [NVARCHAR](100)
,@v_App [NVARCHAR](100)
,@v_User [NVARCHAR](100)
,@v_Spid [NVARCHAR](100)
,@v_Debug [BIT]
,@v_MSG [NVARCHAR](1000)
,@v_SystemName [NVARCHAR](100)
,@v_Connect_Type_ID [INT]
,@v_RowCount [INT]
,@v_Count [INT]
,@v_Version [INT]
,@v_MSSQL_ID [INT];
/* Define Variables */
SELECT @v_Now = GETDATE()
,@v_DB = DB_NAME()
,@v_Obj = '[DBCATCH].[dbo].[PU_BatchDetail_ADD]'
,@v_App = APP_NAME()
,@v_User = ISNULL(ORIGINAL_LOGIN(), USER_NAME())
,@v_Spid = CONVERT([NVARCHAR](25), @@SPID)
,@v_Debug = 0;
IF @p_Rank IS NULL
BEGIN
SELECT @p_Rank = ISNULL(MAX([Rank]) + 1, 1)
FROM [DBCATCH].[dbo].[TU_BatchDetail] (NOLOCK)
WHERE [Batch_ID] = @p_Batch_ID;
END;
IF @p_StartDate IS NULL
BEGIN
SELECT @p_StartDate = @v_Now;
END;
IF @v_Debug = 1
BEGIN -- debug = 1 Ref: 1
SELECT 'REF:1 - Define Static Variables';
SELECT @v_Now AS [GETDATE]
,@v_DB AS [DB]
,@v_Obj AS [OBJ]
,@v_App AS [APP]
,@v_User AS [USER]
,@v_Spid AS [SPID]
,@p_Batch_ID AS [Batch_ID];
END; -- debug = 1
BEGIN TRANSACTION
BEGIN TRY
INSERT [DBCATCH].[dbo].[TU_BatchDetail]
(
[Batch_ID],
[BatchSize],
[OBJECT_ID],
[Entity_ID],
[OBJECT],
[StartDate],
[EndDate],
[Rank]
)
VALUES
(
@p_Batch_ID,
@p_BatchSize,
@p_Object_ID,
@p_Entity_ID,
@p_Object,
@p_StartDate,
@p_EndDate,
@p_Rank
);
END TRY
BEGIN CATCH
SELECT @v_Error = 100001
,@v_MSG = CONVERT(NVARCHAR(2500),
'Error: ' + CONVERT([NVARCHAR](255), ISNULL(ERROR_NUMBER(), -1)) +
' Severity: ' + CONVERT([NVARCHAR](255), ISNULL(ERROR_SEVERITY(), -1)) +
' State: ' + CONVERT([NVARCHAR](255), ISNULL(ERROR_STATE(), -1)) +
' Line: ' + CONVERT([NVARCHAR](255), ISNULL(ERROR_LINE(), -1)) +
' Procedure: ' + CONVERT([NVARCHAR](255), ISNULL(ERROR_PROCEDURE(), @v_Obj)) +
' MSG: Error Inserting into [DBCATCH].[dbo].[TU_Batch] with error:' + ISNULL(ERROR_MESSAGE(), ''));
EXEC [DBCATCH].[dbo].[PU_ErrorLog_ADD]
@p_Error_ID = @v_Error,
@p_System = NULL,
@p_DB = @v_DB,
@p_Obj = @v_Obj,
@p_App = @v_App,
@p_User = @v_User,
@p_ErrorMsg = @v_MSG;
ROLLBACK TRAN;
RETURN @v_Error;
END CATCH;
COMMIT TRANSACTION;
GO
IF OBJECT_ID('[dbo].[PU_BatchDetail_ADD]') IS NOT NULL
BEGIN
PRINT '<<< CREATED PROCEDURE [dbo].[PU_BatchDetail_ADD] >>>';
END;
ELSE
BEGIN
PRINT '<<< FAILED TO CREATE PROCEDURE [dbo].[PU_BatchDetail_ADD] >>>';
END;
GOFinal Step: Update Procedure & Stop Times
The last task in your T-SQL batching is to create an update procedure for the batch detail records. This adds stop times for each nested iteration and for the batch itself.
USE DBCATCH
GO
IF EXISTS(SELECT 1
FROM [dbo].[sysobjects] (NOLOCK)
WHERE [id] = OBJECT_ID(N'[dbo].[PU_BatchDetail_UPD]')
AND OBJECTPROPERTY([id], N'IsProcedure') = 1)
BEGIN
DROP PROCEDURE [dbo].[PU_BatchDetail_UPD];
PRINT '<<< DROPPED PROCEDURE [dbo].[PU_BatchDetail_UPD] >>>';
END
GO
CREATE PROC [dbo].[PU_BatchDetail_UPD]
@p_ActivityLog_ID [BIGINT]
,@p_Batch_ID [UNIQUEIDENTIFIER] = NULL
,@p_Now [DATETIME] = NULL
WITH ENCRYPTION
AS
/*************************************************************************************************/
/* Name : PU_BatchDetail_UPD */
/* Version : 1.0 */
/* Author : Jared Kirkpatrick */
/* Date : 2019-08-24 */
/* Description : Updating the Batch detail log */
/*************************************************************************************************/
/* Date : Version: Who: Description */
/*************************************************************************************************/
/* 2019-08-24 : 1.0 : REB: Initial Release. */
/*************************************************************************************************/
SET NOCOUNT ON;
/* Declare Variables */
/* Declare Variables */
DECLARE @v_Now [DATETIME]
,@v_Domain [NVARCHAR](100)
,@v_IPAddress [NVARCHAR](100)
,@v_SQL [NVARCHAR](4000)
,@v_UserName [NVARCHAR](100)
,@v_PW [NVARCHAR](100)
,@v_Error [INT]
,@v_ActivityLog_ID [INT]
,@v_DB [NVARCHAR](100)
,@v_Obj [NVARCHAR](100)
,@v_App [NVARCHAR](100)
,@v_User [NVARCHAR](100)
,@v_Spid [NVARCHAR](100)
,@v_Debug [BIT]
,@v_MSG [NVARCHAR](1000)
,@v_SystemName [NVARCHAR](100)
,@v_Connect_Type_ID [INT]
,@v_RowCount [INT]
,@v_Count [INT]
,@v_Version [INT]
,@v_MSSQL_ID [INT];
/* Define Variables */
SELECT @v_Now = GETDATE()
,@v_DB = DB_NAME()
,@v_Obj = '[DBCATCH].[dbo].[PU_BatchDetail_UPD]'
,@v_App = APP_NAME()
,@v_User = ISNULL(ORIGINAL_LOGIN(), USER_NAME())
,@v_Spid = CONVERT([NVARCHAR](25), @@SPID)
,@v_Debug = 0;
IF @v_Debug = 1
BEGIN -- debug = 1 Ref: 1
SELECT 'REF:1 - Define Static Variables';
SELECT @v_Now AS [GETDATE]
,@v_DB AS [DB]
,@v_Obj AS [OBJ]
,@v_App AS [APP]
,@v_User AS [USER]
,@v_Spid AS [SPID]
,@p_Batch_ID AS [Batch_ID];
END; -- debug = 1
BEGIN TRANSACTION
BEGIN TRY
UPDATE [DBCATCH].[dbo].[TU_BatchDetail] WITH (ROWLOCK)
SET [EndDate] = @p_Now
,[Active] = 0
WHERE [OBJECT_ID] = @p_ActivityLog_ID
AND [Batch_ID] = @p_Batch_ID;
END TRY
BEGIN CATCH
SELECT @v_Error = 100002
,@v_MSG = CONVERT(NVARCHAR(2500),
'Error: ' + CONVERT([NVARCHAR](255), ISNULL(ERROR_NUMBER(), -1)) +
' Severity: ' + CONVERT([NVARCHAR](255), ISNULL(ERROR_SEVERITY(), -1)) +
' State: ' + CONVERT([NVARCHAR](255), ISNULL(ERROR_STATE(), -1)) +
' Line: ' + CONVERT([NVARCHAR](255), ISNULL(ERROR_LINE(), -1)) +
' Procedure: ' + CONVERT([NVARCHAR](255), ISNULL(ERROR_PROCEDURE(), @v_Obj)) +
' MSG: Error Updating [DBCATCH].[dbo].[TU_BatchDetail] with error:' + ISNULL(ERROR_MESSAGE(), ''));
EXEC [DBCATCH].[dbo].[PU_ErrorLog_ADD]
@p_Error_ID = @v_Error,
@p_System = NULL,
@p_DB = @v_DB,
@p_Obj = @v_Obj,
@p_App = @v_App,
@p_User = @v_User,
@p_ErrorMsg = @v_MSG;
ROLLBACK TRAN;
RETURN @v_Error;
END CATCH;
COMMIT TRANSACTION;
GO
IF OBJECT_ID('[dbo].[PU_BatchDetail_UPD]') IS NOT NULL
BEGIN
PRINT '<<< CREATED PROCEDURE [dbo].[PU_BatchDetail_UPD] >>>';
END;
ELSE
BEGIN
PRINT '<<< FAILED TO CREATE PROCEDURE [dbo].[PU_BatchDetail_UPD] >>>';
END;
GOThat completes the objects needed to make our T-SQL batching framework functional, and completes part 4 of the series. In part 5, the final installment, we’ll go over these batching features and wrap it all up.




{kind=link}