One of the all-time best performing posts on our blog is from Randy Knight and outlines how to use Linked Servers the right way. In this post from Steve Rezhener, he shows how OPENQUERY can make all the difference with Linked Servers.
Introduction (the good)
If you are not familiar with a linked server concept in SQL Server, don’t worry, you probably haven’t needed it yet. You are fortunate to source all your data needs from a single database server, and that is fine. Or maybe you are consuming your SQL Server needs from Azure Single Database or AWS RDS (both public cloud solutions don’t support linked server out of the box).
Most likely this is going to change (Azure VM and AWS EC2 have full support) and you will have to join data between multiple database servers, or even between different RDBMS systems. For example: All the transactional sales data is stored in SQL Server, but all the analytical sales data is stored on another SQL Server server (this could even be MySQL).
This is where Linked Server comes in handy, especially at the data discovery phase. When building a prototype needs to happen quickly and there is no time to adhere to the best practices, Linked Server can be the answer.
This blog post outlines the pros and cons of linked servers in SQL Server as well as how to reduce the cons of using an OPENQUERY.
Linked Servers Basics
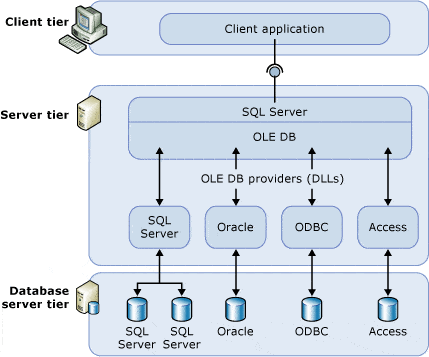
According to Microsoft, linked servers enable the SQL Server Database Engine and Azure SQL Database Managed Instance to read data from the remote data sources and execute commands against the remote database servers (for example, OLE DB data sources) outside of the instance of SQL Server.
Linked Server is a pure convenience feature. With very little to no code changes, you can suddenly join multiple tables between local and remote/cloud servers. For example, let’s use WideWorldImporters transactional database
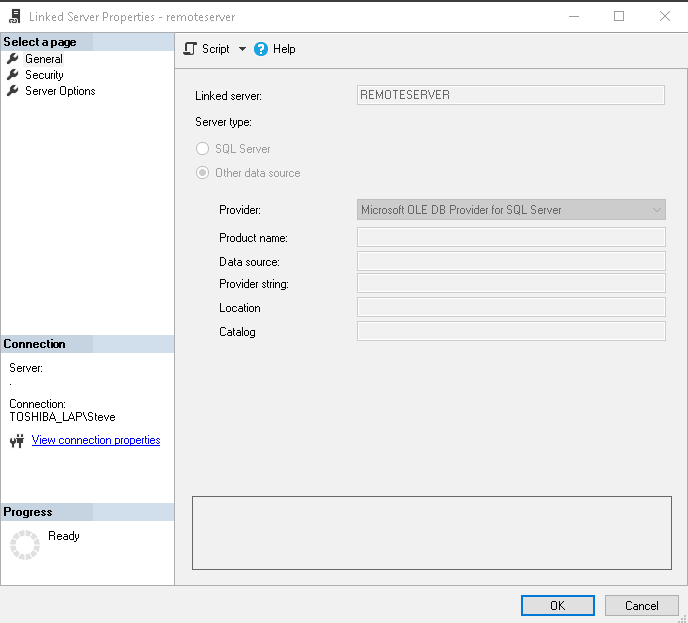
Linked Server effectively removes the need for a solution that will move and synchronize the data. You just setup a Linked Server (see Fig #2) and add a Linked Server reference in front of the three-part naming convention (see Fig #3). That’s all. A small price to pay for lots of convenience.

Problem (the bad)
While the Linked Server feature makes it easy to join tables between two or more different servers, it’s not free and it comes with a price tag: performance overhead. While joining a few small tables might not add noticeable pressure to the server, joining 3-5 fairly large remote tables might introduce locking and blocking and increase the run-time from seconds to minutes.
The main problem occurs when you run queries against a remote server, which is not healthy. When SQL Server runs a query with Linked Server, it will use the least optimal execution plan due to lack of knowledge of those remote tables. Meaning, your local SQL Server is clueless on remote table indexes and statistics, so it might use an incorrect joining mechanism and might be grossly inefficient.
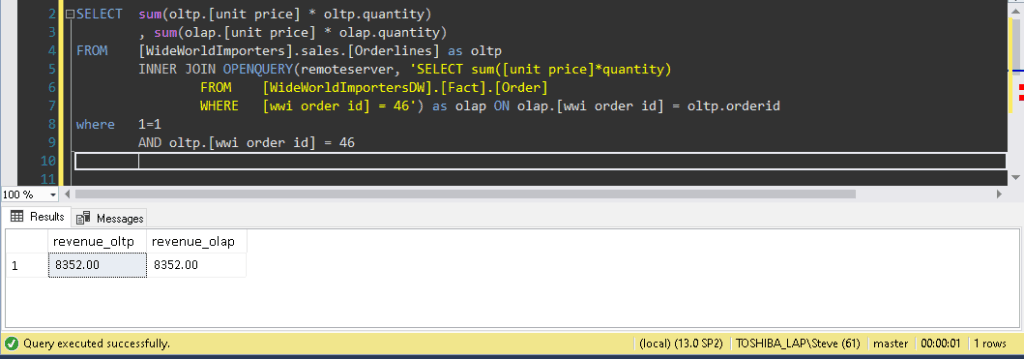
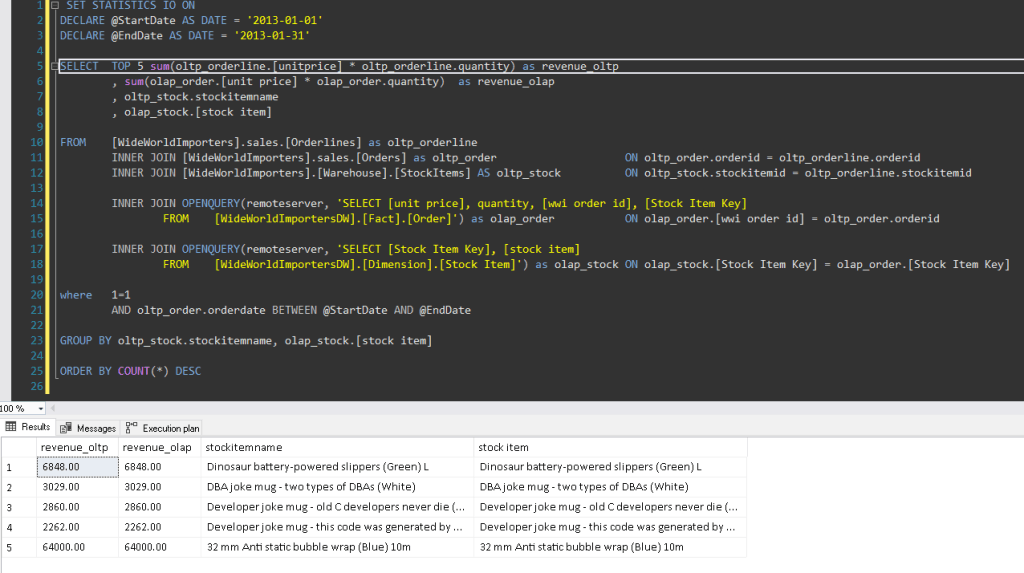
For example, if you had to join all January 2013 orders between OLTP and OLAP tables and compare revenue per product while showing the five top contributors, we might build the following query (see Fig #4) to achieve that goal:
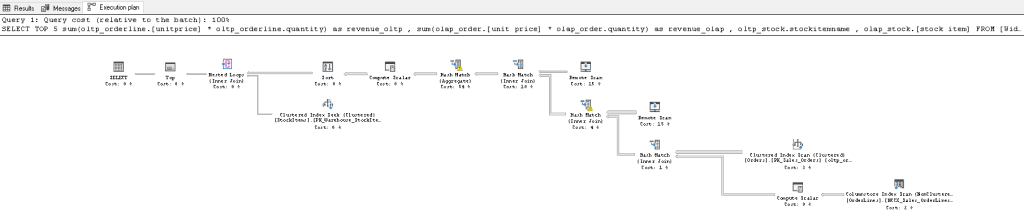
Reviewing Statistics IO (see Fig #5) and execution plan details (see Fig #6), we see:


As you might notice (far right), 93% of the query execution cost goes to a “mysterious” remote query.
Solution (a way to make it perfect)
One of the easiest ways to fix performance problems with a linked server is to run it via OPENQUERY.
What is OPENQUERY? According to Microsoft, OPENQUERY executes the specified pass-through query on the specified linked server. This server is an OLE DB data source. We can reference OPENQUERY in the FROM clause of a query as if it were a table name. We can also reference OPENQUERY as the target table of an INSERT, UPDATE, or DELETE statement. This is subject to the capabilities of the OLE DB provider. Although the query may return multiple result sets, OPENQUERY returns only the first one.
One of the main advantages of OPENQUERY is remote execution. This means the local server sends the query to the remote server with knowledge of those remote tables that are now local to the query. By the way, remote execution also enables the use of native syntax of the remote server, so you can take advantage of other RDBMS system performance tricks.
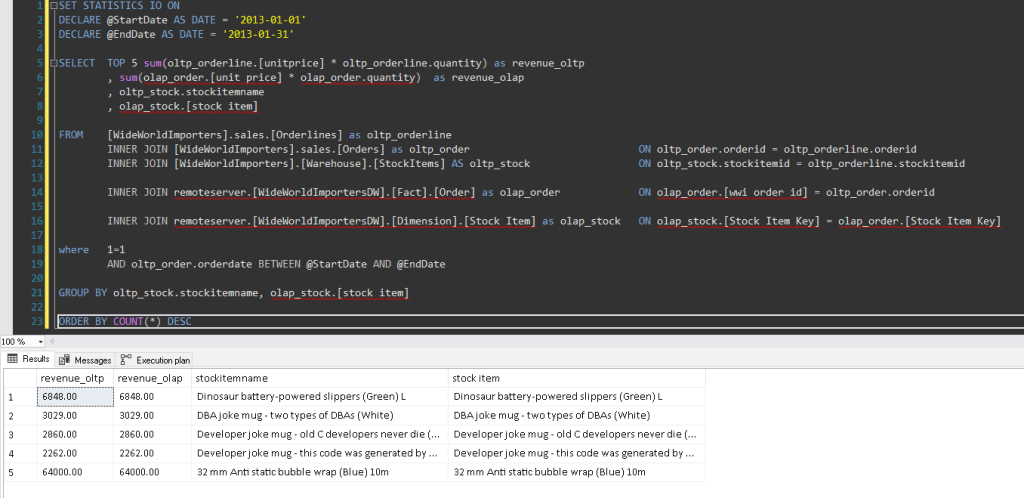
Here is how our original query will look with an OPENQUERY (see Fig #7). It’s still using the same linked server, but it happens indirectly now with an OPENQUERY.
When reviewing Statistics IO (see Fig #8) and execution plan details (see Fig #9), we now see:

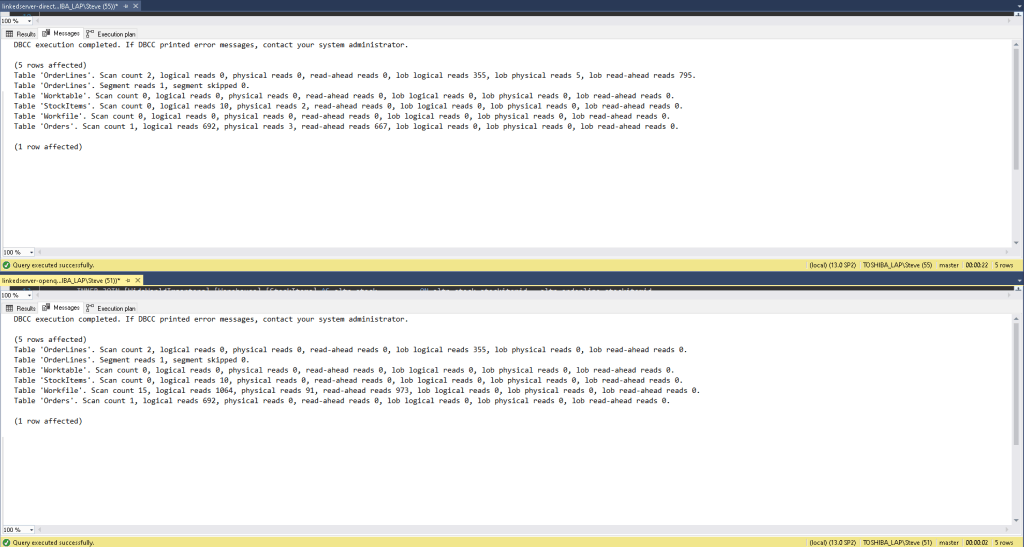
Let’s compare Statistics IO and execution plans to see the differences between direct query linked server usage vs. an OPENQUERY linked server.
The most noticeable differences are:
- WorkFile reads in Statistics IO (see Fig #10)
- Remote Query 93% cost vs. most distributed cost in Execution Plan (see Fig #11) and partially replaced with Remote Scans.
Why Does It Work?
The main reason OPENQUERY will usually perform better is knowledge of the table in terms of indexes and stats, knowledge that a direct linked server doesn’t have.
As you can see, we have managed to cut the run-time from 22 seconds (using direct link server) down to 2 seconds (using OPENQUERY). Additionally, we can add indexes specific to the query to make OPENQUERY even faster.
Disclaimer
Since nothing is certain in this life other than taxes and death, your mileage may vary (“YMMV”). Please test it (preferably using DBCC FREEPROCCACHE) prior to deployment. In addition the query above that reduced run-time by 11 times, I also scored a drastic performance gain by using OPENQUERY in one of the clients. In that example, replacing all three direct linked server references reduced run-time by 10 times, to just a few seconds.
The only caveat with OPENQUERY, since it can’t accept parameters, are the use of dynamic SQL and “fighting the quotes” – making sure to escape the single quotes that are internally used by a SQL Server to identify literal, i.e. text.




{kind=link}
This Post Has 2 Comments
good one 🙂
Very Good indeed!
Comments are closed.