
SQL Server 2022 introduced of a number of new features, and one of the more interesting of these is Contained Availability Groups. These are very close to normal Availability Groups, but they have some very important differences. In this post, I’ll compare the new features included and some of the pitfalls that we’ve come across with their implementation.
Always On Availability Groups
First of all, it’s important that we understand what a normal Availability Group is.
SQL Server 2012 introduced Availability Groups, which are a solution to provide high availability and disaster recovery. They allow you to replicate databases across multiple SQL Server instances. These instances are covered by a Windows Server Failover Cluster which manages the AG.
You can use AGs to scale out an application by making read only secondary replicas available for a front-end application to read from. The most common type we see, however, provides the opportunity to move our workload (via a fail over) and run either node as the primary node. This provides the high availability of the involved databases and allows for maintenance and patching without taking the databases offline.
When you connect to an AG you should connect via the listener. The listener is a virtual network name that you can use which connects to the current primary node, whichever server that is. This is what points clients towards the primary node so that we don’t need to change any code to do this.
Please note that databases that are in the AG and also on the secondary node are read only databases on the secondary node. You can’t replicate to the primary from the secondary, so you can only perform read only processes (assuming this setting is enabled).
Here’s an example of what an AG looks like with two nodes, a primary and a secondary.
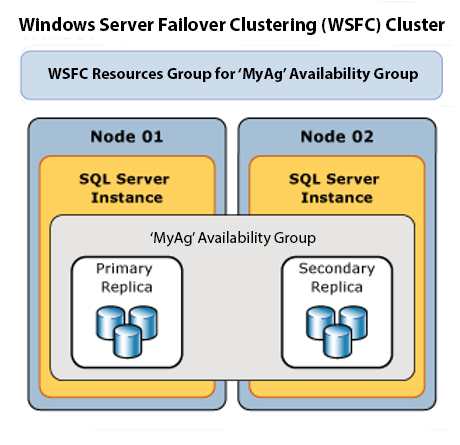
AGs allow the ‘offloading’ of tasks from the primary to the secondary nodes. If you’re unable to run DBCC CHECKDB against your primary node but you still want to run it, you can offload that to the secondary node in a pinch (there are some caveats with this, but it’s not uncommon). You can also complete backups against the secondary node if necessary (due to database size for example). This can reduce the amount of work your primary replica has to perform if there are bottlenecks around these processes.
The thing that’s always been tricky with AGs is that it’s only the user databases that are replicated between the nodes. Anything that sits outside of these is not replicated. Anything stored in system databases is a great example here. The msdb database contains all SQL Server Agent Jobs on the server. This database does not get replicated over to the secondary node in an AG. This means has some implications:
- You have to make sure when deploying Agent jobs that you install them on both nodes. This includes modifications as well as new jobs.
- These jobs have to be aware that they’re in an AG. As the databases on the secondary node are read only, chances are a lot of your agent jobs will not want to run on the secondary. This is a simple but essential check that usually stops them from running on the secondary node.
- The job history is stored in msdb and as such is only stored on whatever node is currently primary.
Contained Availability Groups
Contained AGs are very similar to traditional AGs. They have the same basic structure and functionality with a few very important differences.
Contained System Databases
Whereas in traditional AGs the system databases are not replicated, a Contained AG has its own master and msdb databases that are named after the AG (e.g. in a Contained AG called “MyAg” you would have a “MyAg_master” and “MyAg_msdb” database). These databases are replicated to all nodes in the same way a user database is.
The most obvious advantage here is that all Agent jobs are now contained within the AG and therefore are replicated to all nodes. This removes the requirement for them to be AG aware, as they are only going to be scheduled to run against the primary node. The job history and other system tables are also replicated so if a failover happens then history is maintained.
You do still have the traditional msdb and master on each node. However, SQL Server does not synchronize them inside the Contained AG in the same way it handles the contained system databases.
Gotchas
Contained AGs sound great for maintaining things like Agent jobs. But there are a couple of things to consider with these:
- Remember those agent jobs we offloaded to the secondary node? Yep, can’t do that if we have the agent jobs in the contained msdb database. The jobs can only run against the primary node.
- Replication doesn’t work with Contained AGs. If this feature is essential for you then you may want to consider other options.
- The GUI does not currently support manual seeding and this option is not documented at the moment. You can totally do it with T-SQL but you’re not going to find Microsoft docs on this yet.
- Contained AGs do not support distributed AGs. DAGs are a combination of two AGs, usually distributed either geographically or between networks (e.g. one AG on premises & one in the cloud).
- You and your scripts need to be aware that when you connect to the listener of the contained AG that the msdb and master databases that you see will be the contained AG version, not the actual system databases on the replica. If connecting to each node directly the Contained AG system databases will show as user databases with names such as MyAg_msdb and MyAg_master.
Solution for Agent Jobs
If you need to run agent jobs against the secondary node, we can use the functionality of the traditional AG (even if we’re using a contained AG). Even though we have a contained msdb we still have the classic msdb for this node which is not replicated.
We’ll have to install the job on each node and must ensure they’re AG Aware (and only run against the secondary node). This removes some of the advantage of using Contained AGs and moves us back to the traditional approach. But, it’s the way to get the functionality that we need.
Solution for System Databases
The solution here all depends on whether you actually have an issue with this in your code. This is very much a case-by-case basis but effectively, are you using or creating objects in the master or msdb databases? If you’re not, then you don’t have to worry, but if you are then you’ll have to consider carefully how you treat these databases in your code.
To reiterate too, you can absolutely have agent jobs in the Contained msdb as well as the local msdb on the server. If you’re checking your agent jobs then you’ll have to remember to query the two separate msdb databases in order to get accurate results.
In 2023, our Founder and Principal Consultant, Randy Knight, hosted a webinar that looked at compelling features of SQL Server 2023, including Contained AGs. You can view that specific portion of the webinar, including a very handy and thorough demo, here.
Contained Availability Groups have some great benefits, but (as with most things SQL Server) some pitfalls to be aware of. Play around with them and, if you’re need help, let us know.




{kind=link}
This Post Has One Comment
Pingback: Contained Availability Groups in SQL Server 2022 – Curated SQL
Comments are closed.