
There is a popular practice among developers to use globally unique identifiers (GUIDs) as primary keys. At first glance, it seems like a great solution. They are guaranteed to be unique and can be generated anywhere, avoiding a round trip to the database just to get the unique key. While this sounds great in theory, there are some serious performance issues that can be caused by this in a SQL Server database. In this article we’ll take an in-depth look at just one of these.
The first and most damaging thing that GUIDs cause is severe index fragmentation. To understand this, we need to review how clustered indexes work in SQL Server. The clustered index for a table or view determines the physical order of the rows on a data page. So we like to make sure we are clustering on a value that is continuously increasing, like an integer generated by the IDENTITY property or via a sequence. By doing this we ensure that new data always gets added to the end of the table and pages are filled sequentially. The very definition of a GUID is that it is not sequential. So every time a new row is inserted, SQL Server has to move things around to make room for it in the correct place. Not only is this an expensive operation, but a GUID will never be accessed in a range so we lose that benefit of a good clustering key as well. If a page is full and we need to insert a row into it, we get a Page Split, meaning SQL Server has to allocate a new page, move the rows that spill off the original page to it, and then add our new row to the original page.
To illustrate this, let’s create a simple table with a UNIQUEIDENTIFIER data type as the clustering key, using the NEWID() function to generate a GUID. With CHAR data types for the AccountName and AccountDescr columns, these rows will be large so we can create at table with a lot of pages very quickly. We’re also including an InsertOrder column so we can see how data gets moved around.



CREATE DATABASE TestDB
GO
USE TestDB
GO
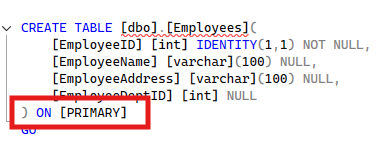
CREATE TABLE Account (
AccountID UNIQUEIDENTIFIER PRIMARY KEY CLUSTERED DEFAULT NEWID()
,AccountName CHAR(50)
,AccountDescr CHAR(2000)
,InsertOrder INT IDENTITY(1,1)
)
GO
To view fragmentation as we go through this exercise, we’ll use the following query as we add data to the table.
SELECT
OBJECT_NAME(OBJECT_ID) AS ObjectName
,index_id
,index_type_desc
,page_count
,avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('Account'),1,NULL,null)
If we execute this query immediately after creating the table, we get the following results. The table is empty so this makes sense.
![]()
Now let’s add some data. We’ll start with just a single row.
INSERT Account DEFAULT VALUES
GO
As we add rows to the table, we’ll use the undocumented function sys.fn_PhysLocFormatter to see exactly where in the database the rows are going. The function returns the database file, page, and slot on the page where the row exists. In the output below, we can see that our single row is on Database File 1, Page 275, Slot 0. As we add more rows, we’ll be able to see the shuffling that is going on.
SELECT *, sys.fn_PhysLocFormatter(%%physloc%%) FROM Account![]()
Executing our DMV query again and we see that with just a single row, we get just 1 page and no fragmentation.
![]()
Now let’s add 10 more rows.
INSERT Account DEFAULT VALUES
GO 10
SELECT *, sys.fn_PhysLocFormatter(%%physloc%%) FROM Account ORDER BY 5
GOYou can visually see the fragmentation and re-ordering of the rows that has occurred here. The InsertOrder tells us the order the rows came into the table, but things have been shuffled around because of the GUID clustering key. Looking at the index stats, we now have 6 pages in this table and we are over 83% fragmented.


The last thing we’ll look at here is the volume of page splits. Let’s insert 1,000,000 rows this time and watch the page split activity while we’re doing it. We’ll do that by monitoring the Page Splits / sec performance monitor counter while the inserts are running.
INSERT Account DEFAULT VALUES
GO 1000000
As you can see, we are averaging over 300 page splits per second. Pretty much every insert is a page split in this scenario.

Looking at the index stats, we have 499,975 pages and we are over 99% fragmented. It’s pretty much impossible to avoid fragmentation in a situation like this.
![]()
So what’s the performance problem?
The main place you’ll see this problem manifest itself is in excessive disk I/O. Because the data is scattered all over the place, doing things like getting multiple rows from a single page won’t usually happen. So you’re seeing a 1:1 or worse ratio of rows to logical reads.
The other issue is that you are touching almost every page in your index over the course of a day. We have a customer who contacted us because their differential backups were just as big as the full backup, even on the first day. They were doing a full backup on Sunday night and differentials on Mon-Saturday. Monday’s differential was just as big as the full. They wanted to know why and if there is really a point to doing differential backups.
As soon as I heard their issue, I knew the next question to ask. Are you using GUID’s for clustering keys? Sure enough, every table in the database was clustered on a uniqueidentifier colulmn. The way differential backups work is that they backup all the data pages that have changed since the last full backup. So what this tells us is that pretty much every page in the database was being written to on a daily basis. This was for a 1TB database.
How to solve it
I love performance engagements where the problems tend to be “low hanging fruit.” Configuration issues, missing indexes, query tuning, etc. At the other end of the spectrum is problems like this because there is not an easy fix. It’s a core architectural issue that requires data model changes at the very foundation of the system. I have one customer with this problem who now understands it but is not willing to fix it due to the cost. We identified the problem almost four years ago and they haven’t been able to fix it yet. And their performance problems just keep getting worse as their database continues to grow.
In SQL Server 2005, Microsoft came out with the NEWSEQUENTIALID() function to try to alleviate some of the pain if you happen to be generating the GUIDs in the database. While it sounds like a great idea, there are two main problems. First, they are not really sequential, at least not over the long term. More importantly, most people who are using GUIDs are generating them on the client.
This is a great example of a problem that would be easy to avoid at design time when the database is first being created but is a huge undertaking to fix after you’re in production.



This Post Has 8 Comments
Wouldn’t using a regular heap table also be an option? Since the data in the table isn’t stored in index order page splits should be greatly reduced.
The problem with that is that you’re just moving the problem. In a heap, you’ll need a nonclustered index on the primary key. The nonclustered index will suffer from the same problems as the clustered index described above. And unless you add a bunch of columns to it, you’ll also be incurring a key lookup every time you use it.
This brings up a good point though. I have had customers who tried to fix this problem by adding an identity field to the table and clustered on that, turning the primary key into a nonclustered unique index. Just like above, that just moves the problem into another index and introduces some new ones as well.
Generally speaking, heaps are usually a bad idea in SQL Server.
So… with new sequential guide if the dB is generating, we remove the second problem. When you say they aren’t really sequential over the long term, what do you mean? What sets the sequence? Do gaps get created and if so, what triggers this? Seems like speed of SQL Server reading the GUID versus an int would be a problem… is it? What fix did you recommend to your customer 4 years ago?
Stay tuned for a followup article that will cover both of these items. The other big issue I’ll cover is storage. GUID’s are much larger than the corresponding integer datatypes.
Hi there, Randy,
You, good Sir, are invited to a presentation on GUIDs on the 28th of July, 2021. It will change your mind about most of what you’ve stated above. In the end, I demonstrate that I can add 100,000 rows per day into a Random GUID Clustered Index for 58 straight days (that’s 5.8 MILLION rows) with almost no page splits, less than 1% fragmentation, and no index maintenance during the entire period. Here’s the link to the event…
https://eightkb.online/
To summarize, I destroy the myth of GUID fragmentation and I lay waste to the current “Best Practices” for index maintenance that most of the world follows. I also demonstrate how ever-increasing indexes and the use of NEWSEQUENTIALID() can make things really bad and how we can actually use Random GUIDs to PREVENT fragmentation.
I don’t know you personally but I believe you’re going to really enjoy this one. Heh… water cooled helmets are optional but strongly recommended. 😀
Hi Jeff,
The 8KB event was already on my schedule. I look forward to your session … this article is 7 years old so I look forward to updating it after the event.
Randy
Thank you for the feedback, Randy. Much appreciated. I’m pretty sure you won’t be disappointed and I’d love any feedback you have. “See” you on Wednesday.
Just curious. Did you watch the presentation on EightKB?