
 Indexed View(s)
Indexed View(s)
An indexed view is a view where the result set from the query (the view definition) becomes materialized in lieu of the virtual table result set of a standard (non-indexed) view. Many times we see that an indexed view would be created to help improve performance. Far too often, an indexed view is created without consideration for the costs of the indexed view. In this article, I hope to cover some of the more important costs that are frequently overlooked when considering an indexed view as a performance panacea.
The Setup
To demonstrate the overlooked costs of indexed views, I have decided to use the AdventureWorks2014 database (if you don’t have this sample database, you can get your copy here). I will create a view in that database and then I will add a few indexes to that view. Prior to sharing the entire setup, and like all good DBAs, I need to first grab a baseline. For this baseline, I am doing nothing terribly complex. I will just grab table sizes and storage information for the entire database.
Here are my results for the size of the objects within the AdventureWorks2014 database:

These results show that the largest object in the database happens to be the Person.Person table at just about 30MB. Not terribly large, but the database is not terribly large as a whole. Let’s see what happens when I add a materialized view, based on the Person.Person table, to the mix. Here is the definition of that view along with the indexes that I will add to help the performance of some essential production related queries.



USE [AdventureWorks2014];
GO
CREATE VIEW [Person].[vPerson]
WITH SCHEMABINDING
AS
SELECT pp.BusinessEntityID
, pp.FirstName
, pp.LastName
, sp.[StateProvinceID]
, sp.[StateProvinceCode]
, sp.[IsOnlyStateProvinceFlag]
, sp.[Name] AS [StateProvinceName]
, sp.[TerritoryID]
, cr.[CountryRegionCode]
, cr.[Name] AS [CountryRegionName]
, pbe.AddressTypeID
, pp.AdditionalContactInfo
, pp.Demographics
FROM [Person].[StateProvince] sp
INNER JOIN [Person].[CountryRegion] cr
ON sp.[CountryRegionCode] = cr.[CountryRegionCode]
INNER JOIN Person.Address pa
ON sp.StateProvinceID = pa.StateProvinceID
INNER JOIN Person.BusinessEntityAddress pbe
ON pbe.AddressID = pa.AddressID
INNER JOIN Person.Person pp
ON pp.BusinessEntityID = pbe.BusinessEntityID
WHERE pbe.AddressTypeID = 2;
GO
CREATE UNIQUE CLUSTERED INDEX CI_vPersonID ON Person.vPerson(BusinessEntityID);
CREATE INDEX IX_vPersonName ON Person.vPerson(FirstName,LastName);
CREATE INDEX IX_vPersonState ON Person.vPerson(FirstName,LastName,StateProvinceID,StateProvinceCode,StateProvinceName);After executing all of that code to create this new view with its indexes, I have the following size results:

The creation of this view has chewed up a bunch of storage. It has jumped right up to the number two spot on the biggest objects list within this database. You can see that differences by comparing the highlighted rows to the previous image. The vPerson view is highlighted in red in this second image to help point it out quickly.
Surely this must be a contrived example and people don’t really do this in the real world, right? The answer to that is simply: NO! It DOES happen. I see situations like this all too often. Far too often, large text fields are added to an indexed view to make retrieval faster. I have mimicked that by adding in two XML columns from the Person.Person table. This is definitely overkill because a simple join back to the table based on the BusinessEntityID would get me those two columns. All I have effectively done is duplicated data being stored and I have achieved that at the low low cost of increased storage of 25% for this small database. If you are curious, the column count between the Person.Person table and this new view is 13 columns each.
I call the 25% increase storage cost a significant increase. An increase of 25% in storage for a single materialized view is not an uncommon occurrence. I have seen multi-terabyte databases with 25% of the total data storage being caused by a single view. If you are tight on storage, any unexpected data volume increase can cause a non-linear growth in data requirements to occur just because of the presence of indexed views. Take that into consideration when presented with an option to either performance tune the code or to take a short-cut and create an indexed view.
Band-aid Performance
I alluded to the use of indexed views as a cog to help improve performance. This is done by taking the query that sucks and turning it into a view. The thought is that it will run faster because an index is created specifically for that data set. Generally the performance gains from using an indexed view, to camouflage the bad query, are seen when the query is complex. Unfortunately, the query I provided for this article is not terribly complex. Due to the simplicity of the first example, let’s look first at the execution plan for another query that runs terribly slow but is also not terribly complex:
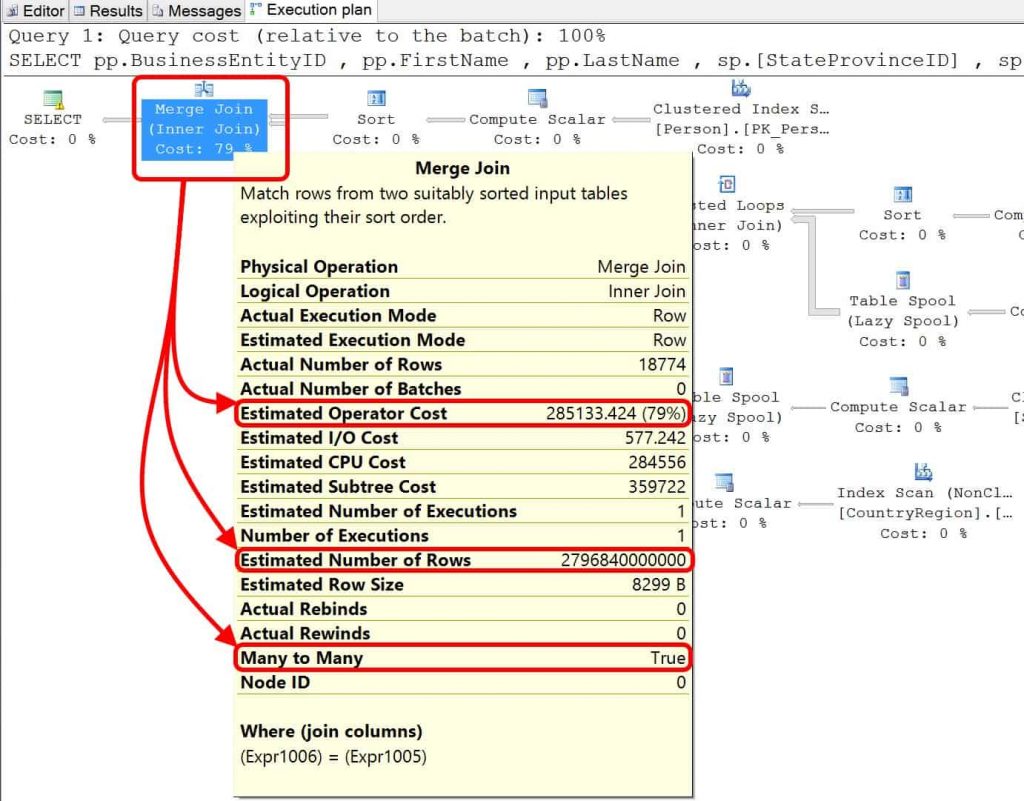
There are a few table spools and index scans. The most costly operator of the bunch appears to be a merge join with a many-to-many join operation. The indexed view in this case does give me a very significant improvement on this query (look at that estimated cost and then the estimated number of rows). What if I could tune the query a little and avoid the all of storage cost? Let’s see!
Consider the base query for this new view:
SELECT pp.BusinessEntityID
, pp.FirstName
, pp.LastName
, sp.[StateProvinceID]
, sp.[StateProvinceCode]
, sp.[IsOnlyStateProvinceFlag]
, sp.[Name] AS [StateProvinceName]
, sp.[TerritoryID]
, cr.[CountryRegionCode]
, cr.[Name] AS [CountryRegionName]
, pbe.AddressTypeID
, pp.AdditionalContactInfo
, pp.Demographics
FROM [Person].[StateProvince] sp
INNER JOIN [Person].[CountryRegion] cr
ON RTRIM(LTRIM(sp.[CountryRegionCode])) = RTRIM(LTRIM(cr.[CountryRegionCode]))
INNER JOIN Person.Address pa
ON RTRIM(LTRIM(sp.StateProvinceID)) = RTRIM(LTRIM(pa.StateProvinceID))
INNER JOIN Person.BusinessEntityAddress pbe
ON RTRIM(LTRIM(pbe.AddressID)) = RTRIM(LTRIM(pa.AddressID))
INNER JOIN Person.Person pp
ON RTRIM(LTRIM(pp.BusinessEntityID)) = RTRIM(LTRIM(pbe.BusinessEntityID))
WHERE RTRIM(LTRIM(pbe.AddressTypeID)) = 2;Looking at the query, you may be asking yourself why use so many trim functions on each of the joins? This is an extreme that can be easily fixed. None of the fields in the joins should need to be trimmed since they are all numeric in this case. Starting there and removing all of the function use in the joins should provide significant improvements in query speed and without the use of a view. Testing it out would yield similar performance results to the first view in this article. This small change would cause the query to complete in 1 second compared to about 90 seconds. That is a huge gain, and without the added cost of increased storage use.
Do I really see stuff like this in the field? Yes! Spending a little time to fix the root of the problem rather than looking for a quick fix and performance can be spectacular. There are times, though, that an indexed view may be an absolute requirement. That would be perfectly fine. There are times when it is warranted and there is no way around it. If an indexed view is an absolute must, then there are a couple more considerations to be taken into account.
Disappearing Act
I showed previously that the indexed view requires storage space and showed that the new view created quickly claimed its place as the second largest object within the database. Now, to stage the next segment, I will show once again that the indexes are present and consuming disk space. This can be shown via the following query:
SELECT o.name AS ObjName
, i.name AS IdxName
, SUM(ps.page_count) AS page_count
, SUM(ps.record_count) AS record_count
, SUM(ps.page_count) / 128.0 AS SizeMB
FROM sys.indexes i
INNER JOIN sys.objects o
ON i.OBJECT_ID = o.OBJECT_ID
INNER JOIN sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL,
'detailed') ps
ON ps.OBJECT_ID = o.OBJECT_ID
WHERE o.name LIKE 'vperson%'
GROUP BY o.name
, i.name;And the results of that query should look something like the following (quick reminder that I created a new indexed view for the second demo and these results will be based on that second view):
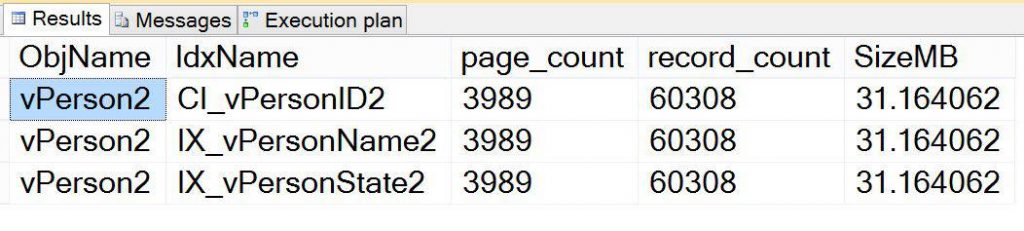
Now that we know the index is present and consuming space, time to make a change to the view and see what happens. I am proceeding under the premise that I have determined that including the two XML columns in the view are completely unnecessary and are the cause of too much space consumption. I can reap the benefits of the view at a fraction of the cost if I ALTER the view and remove those columns. So I will proceed by issuing the following ALTER statement:
ALTER VIEW [Person].[vPerson2]
WITH SCHEMABINDING
AS
SELECT pp.BusinessEntityID
, pp.FirstName
, pp.LastName
, sp.[StateProvinceID]
, sp.[StateProvinceCode]
, sp.[IsOnlyStateProvinceFlag]
, sp.[Name] AS [StateProvinceName]
, sp.[TerritoryID]
, cr.[CountryRegionCode]
, cr.[Name] AS [CountryRegionName]
, pbe.AddressTypeID
FROM [Person].[StateProvince] sp
INNER JOIN [Person].[CountryRegion] cr
ON RTRIM(LTRIM(sp.[CountryRegionCode])) = RTRIM(LTRIM(cr.[CountryRegionCode]))
INNER JOIN Person.Address pa
ON RTRIM(LTRIM(sp.StateProvinceID)) = RTRIM(LTRIM(pa.StateProvinceID))
INNER JOIN Person.BusinessEntityAddress pbe
ON RTRIM(LTRIM(pbe.AddressID)) = RTRIM(LTRIM(pa.AddressID))
INNER JOIN Person.Person pp
ON RTRIM(LTRIM(pp.BusinessEntityID)) = RTRIM(LTRIM(pbe.BusinessEntityID))
WHERE RTRIM(LTRIM(pbe.AddressTypeID)) = 2
;
GOTake note of how long this ALTER command takes to complete – nearly instantaneous. That rocks! Right? Let’s look at the indexes to make sure they are still in working order and don’t require a defrag. Based on that, I will re-run that query to check the indexes and sizes – for giggles.
SELECT o.name AS ObjName
, i.name AS IdxName
, SUM(ps.page_count) AS page_count
, SUM(ps.record_count) AS record_count
, SUM(ps.page_count) / 128.0 AS SizeMB
FROM sys.indexes i
INNER JOIN sys.objects o
ON i.OBJECT_ID = o.OBJECT_ID
INNER JOIN sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL,
'detailed') ps
ON ps.OBJECT_ID = o.OBJECT_ID
WHERE o.name LIKE 'vperson%'
GROUP BY o.name
, i.name;This time when the query completes, I get a nice little surprise: I no longer have any indexes on that view. Changing the view definition instantly drops any indexes that were built on that view. If this is done in a production system, imagine the implications and problems that could arise.
Conclusion
In this article, I have covered indexed views and three different considerations that are often overlooked when looking to implement a materialized view. The three considerations for indexed views, as discussed, are: storage, changes to the view, and the band-aid effect. Overlooking the cost of storage can have serious repercussions on the production environment. Implementing an indexed view without attempting to tune the code first could lead to overlooking the storage cost and could end up just being a waste of resources. The last tidbit is that any change to an indexed view will drop the indexes. That is an easily overlooked feature of indexed views. If you forget to recreate the indexes on the view after making changes, you could be looking at a production outage.
There are a couple more critical considerations for indexed views that are often overlooked as well. These additional considerations are blocking, deadlocking, and maintenance. These considerations will be discussed further in a future article.




{kind=link}
This Post Has 2 Comments
Great article. I have also seen these and am glad you’ve presented them and in a straight forward understanding way. I see it as there are rules of thumb for scripts to write, and then there are exceptions, but those should only be well thought out solutions and not just slapped together. Thanks for expressing this.
Thanks Greg.
Comments are closed.