
Maybe a user has reported some data is unavailable, maybe you’ve received an error message on a report that shouldn’t be erroring, maybe you value your job and have CHECKDB scheduled which caught this early. Sometimes you’re blindsided by database corruption and it has to be dealt with. It’s not a fun process, but it’s an essential one.
One of the most common causes of corruption is a break in the chain of data pages in your indexes. The data stored in your SQL Server is stored in pages of 8kb. Each of these pages has metadata stored within, including (but not limited to) the page ID and also the previous and next page IDs. This allows SQL Server to ensure consistency of results. When data is read from a table or index that has a break in this chain, the query will fail and you will get an error showing that there is potential corruption.
When this happens, we have to find the extent of this corruption, as some instances are much easier to deal with than others.
The error message received will show which table is reporting corruption, and sometimes it will give you the index name too. If it doesn’t, then we need to find which index on this table is potentially affected.
The easiest way to do this is to get a list of your indexes. You can either do this in the SSMS GUI or use the query below (replace TableName with your actual table name)



SELECT
o.name AS TableName
,i.name AS IndexName
,i.type_desc AS IndexType
FROM sys.indexes i
INNER JOIN sys.objects o ON i.OBJECT_ID = o.OBJECT_ID
WHERE o.name = 'TableName'
I’m using a copy of the stack overflow database and my indexes look like this;
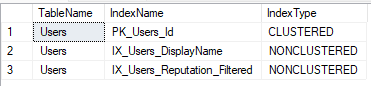
Then we’re going to do a simple select * query against each index individually. To do this, we’ll want to use an index hint (if I catch you doing this in production code, we’ll be having words):
SELECT COUNT(*)
FROM dbo.Users
WITH (INDEX(IX_Users_DisplayName))
If you look at the execution plan of the query you can be sure that it’s using the correct index:
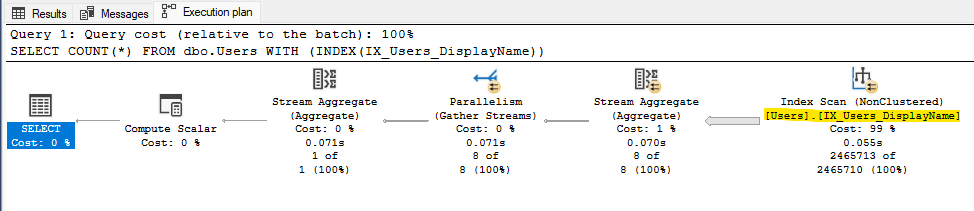
You’ll want to run the same query with all of your indexes. Any with corruption will throw an error. That’s where we need to focus.
Non Clustered Index
If you’re extremely lucky, you’ll have corruption in a non-clustered index. These indexes just contain a copy of your data, not the actual base data itself (which will be in the clustered index if you have one, or in the heap if you don’t).
This means we can just rebuild the index:
ALTER INDEX IX_Users_DisplayName ON Users REBUILD
Now, this operation isn’t free. It’s going to take some time to rebuild the index and use resources (CPU, IO) while it happens. If you’re running Enterprise edition, then you want to take advantage of the ONLINE = ON option too. Otherwise you’ll be taking a lock on the index (and potentially blocking other processes) while it rebuilds. Here’s the documentation.
Once the index has completely rebuilt, you can run the same query as before and it should return the total row count for that index:
SELECT COUNT(*)
FROM dbo.Users
WITH (INDEX(IX_Users_DisplayName))
Congratulations, you’ve fixed the corruption!
Now that the panic has subsided, we want to catch this as early as possible. Double check that you have a schedule for DBCC CHECKDB to be run regularly (we suggest weekly) and, most importantly, that you’re getting notifications when it fails.
Clustered Indexes/Heap Tables
Now, if you find corruption in your clustered index or your heap, then we’ve got a different issue. This is the main structure of how the table is saved on disk and it’s corrupt.
First of all, let’s find out the extent of the problem. With the index hint mentioned previously, we want to select a field that will allow us to distinctly find the rows affected. In a clustered index this will be your primary key, in a heap you will have to look at the columns and work this out yourself.
In my table, we have a clustered index with the clustering key called “Id”:
SELECT Id
FROM dbo.Users
WITH (INDEX(PK_Users_Id))
ORDER BY Id ASC
First thing we’ll do is select the key in an ascending order and let this run. It will return the results until it comes up to the first page that contains corruption.
In my corrupted data, the max Id returned before the error is 2622175. Make a note of your number.
The next thing we’ll do is the same query, but in a descending order;
SELECT Id
FROM dbo.Users
WITH (INDEX(PK_Users_Id))
ORDER BY Id DESC
This will scan the index the other direction. We will wait again until we hit our block of corruption. In my data, this was Id 2622269.
That tells me the range of potential corrupt data is Ids 2622175 to 2622269. This gives a potential data loss of 94 rows of data.
There are a few options of what we can do here to fix this.
Recovering Data
If your corruption is in a clustered index or heap, we may well have some of this data backed up in any non clustered indexes we have on this table. It’s worth selecting all data for the suspect range of Ids and copy into a table elsewhere. To do this, we’ll combine the index hint above with a where clause for the data range we care about.
SELECT
*
INTO dbo.Users_IX_Users_DisplayName
FROM dbo.Users
WITH (INDEX(IX_Users_DisplayName))
WHERE Id BETWEEN 2622175 AND 2622269We want to do this for all non-corrupted indexes. This way, if we lose data, we will be able to recover as much as possible.
Repairs
Once we’re aware of the table with the issues, we don’t need to do a full DBCC CHECKDB in order to fix this. Rather, we can use DBCC CHECKTABLE. There’s a couple of options for CHECKTABLE: we can do a REPAIR_REBUILD or, more likely, REPAIR_ALLOW_DATA_LOSS. Most corruptions issues cannot be fixed with the former, so we likely need to go with the second option.
REPAIR_ALLOW_DATA_LOSS will attempt to fix the consistency issues, but as the name implies, we may well lose some data here.
The official documentation is here.
The basic syntax of what you’ll end up running will look like this:
ALTER DATABASE [StackOverflow2013_Indexed] SET SINGLE_USER;
GO
DBCC CHECKTABLE ('dbo.Users', REPAIR_ALLOW_DATA_LOSS);
GO
ALTER DATABASE [StackOverflow2013_Indexed] SET MULTI_USER;
GOWe’ll set the database to single user mode (a requirement for the repair process), run the repair, and then set it back to multi user mode.
You’ll now want to select all of the rows that are within our range of corruption:
SELECT
*
FROM dbo.Users
WITH (INDEX(PK_Users_Id))
WHERE Id BETWEEN 2622175 AND 2622269In this example, we had a potential 94 rows worth of data corrupted and the repair process saved 87 of them. We only lost 7 rows of our data. And most of the relevant data was recovered from the non-clustered indexes that we backed up before, so we were able to recover most data.
At this point, we can also restore our last known good backup to a new location (a different database name, a different server) and see if we have this data available and non-corrupted. We could then use this and re-insert our data into the current production database.
Availability Groups
It’s worth noting, that, for most repair options, the database will need to be in single user mode. This means that it will first need removing from any availability group, then repairing, then adding back into the AG. Depending upon your database size and hardware, this can be a lengthy process. This also means that during this fix the database will not be available on the secondary node (if you have other processes that read from the secondary).
Important: Because of the above, you’ll definitely need an outage window in order to fix this issue.
Conclusion
Losing data is both a scary thing and also a potential job-threatening incident. We’ve done what we can here to recover the data. But we want to catch this as early as possible. Scheduling a DBCC CHECKDB to run regularly (most people run this over the weekend) can catch these issues early before they become too much of a problem. Plus, you want to be seen as being proactive rather than reactive, right? It’s much better if you catch this and report it up the chain rather than a user finding the problem and surprising you.
If you have any questions, please get in touch and we’d be happy to help.




{kind=link}
This Post Has One Comment
Also worth to mention is that several corruptions can be fixed automatically if you have your database in an Availability Group, see table suspect_pages in MSDB
Comments are closed.