
Full-text search is its own beast. It’s not your regular old index. You’ve got to build either a full-text catalog or a database with one, and inside that catalog live the full-text indexes. The whole point? To let you search text efficiently.
Now, don’t get me wrong—this isn’t like your standard clustered or non-clustered index. Those are great for looking up structured values: exact matches, ranges, you name it. But the minute you need to search inside text—notes, documents, blobs of VARCHAR(MAX), heck, even PDFs—you’re in full-text land.
Why You Might (or Might Not) Want It
Here’s the thing: full-text search is powerful, but it’s also quirky.
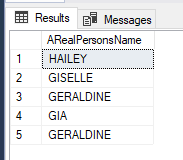
For example, let’s say my name and company were in the database:
A.K. Gonzalez, SQL Solutions Group. Five separate words.
-
If I search for Solutions, it finds it.
-
If I search Sol*, it finds it.
-
If I search Gro*, it finds it.
But if I search for *lez (the end of my last name), no dice. Full-text search only works from the beginning of words. That’s by design. It tokenizes words and builds an index from there. Middle-of-word searches? Nope. That’s not its job.
If you really need *lez matches, you’re falling back to LIKE ‘%lez%’, or you’re getting fancy with n-grams, trigrams, or even throwing in something like Elasticsearch. But out of the box? Full-text won’t do it.
The Pain Points
Here’s what our experts have seen most often with full-text indexes: problems. Specifically, corruption.
The good news is, corruption can be dealt with (usually via a rebuild). But you do need to go in with your eyes open:
-
If you’re searching large object (LOB) types—VARCHAR(MAX), NVARCHAR(MAX), VARBINARY(MAX), etc.—you’re almost guaranteed to need full-text indexes. Otherwise, queries will crawl.
-
Updates are asynchronous. You insert a row, it’s not instantly searchable. SQL Server queues that update and applies it later.
-
They take up space—sometimes more than the data itself.
So yeah, powerful, but fussy.
Best Practices Checklist
If you must use full-text search, here’s how to keep yourself out of trouble:
Setup & Design
-
Use supported data types (NVARCHAR, VARCHAR, VARBINARY(MAX)). Forget the old TEXT/IMAGE types.
-
Only index what you actually need—fewer columns = faster.
-
Pick the right language for your column (stopwords and stemming matter).
-
If you’re indexing documents (Word, PDF, etc.), install the proper iFilters.
Performance
-
Plan for storage overhead. Catalogs can balloon.
-
Remember indexing is asynchronous. New data won’t show up right away.
-
If you’re bulk loading data, disable the index, load, then rebuild.
Maintenance
-
Rebuild (ALTER FULLTEXT CATALOG … REBUILD;) when corruption shows up.
-
Reorganize for lighter cleanup.
-
Monitor crawl status (sys.fulltext_indexes, sys.dm_fts_index_population).
-
Always confirm backups/restores include the full-text catalog.
Troubleshooting
-
Corruption? → Rebuild.
-
Missing rows? → Could be stopwords, population delay, or language settings.
-
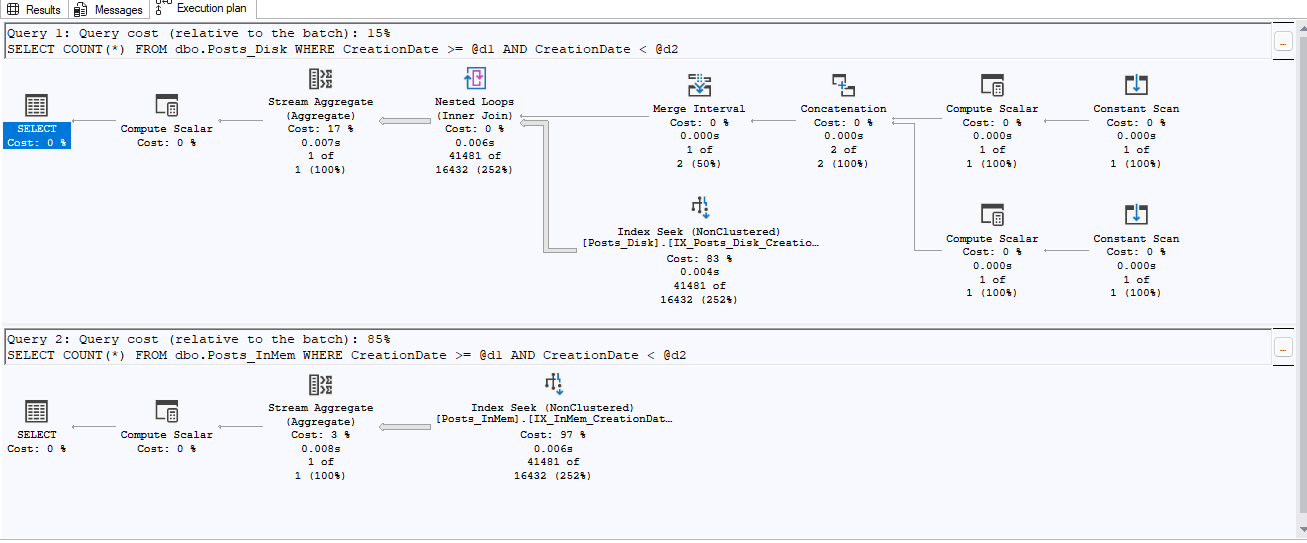
Slow queries? → Check the execution plan to confirm the full-text index is even being used.
-
Need middle-of-word searches? → Sorry, that’s not what full-text is for.
Final Thoughts
Full-text search is a specialized tool. Use it for natural language text—articles, documents, long descriptions. Don’t waste it on structured lookups. It’s easy to have problems with, but with the right care and feeding, it’ll do its job.
And when it goes sideways? Nine times out of ten, a rebuild puts it back in line.

{kind=link}