One of the fundamental and basic responsibilities of a database administrator is ensuring the protection and safekeeping of company data. Information, or data, is knowledge and power for any organization. Therefore, the task of protecting the data cannot be understated. This blog won’t list the reasons why you should back up your data (but as a summary, hardware failures, user errors, and natural disasters come to mind), so we’ll jump right into the basics of SQL Server backups.
Backing up the data is the only way to safely protect it. As a database administrator, it falls upon you to know and implement the best strategy and plan for backing up your data based on your organization’s business needs and requirements.
Transaction Log
In order to understand backups, a quick review of the SQL server transaction log is in order. When a data modification statement (i.e. INSERT, UPDATE, DELETE DML or any DDL) executes against a SQL Server database, the change is first written to the transaction log. This will ALWAYS happen, regardless of recovery model, types of backups, or any other setting. In order to commit a transaction, it must be written to the log and “hardened”, which means writing it to disk. This is how SQL Server ensures durability. A separate process called CHECKPOINT writes the changes to data pages to disk.
Database Recovery Model
In order to fully understand how SQL Server backups work, we must first understand recovery models. The recovery model of a database determines when database transactions are cleared from the transaction log and your options for restoring the database. This is sometimes called truncating the log. SQL Server has three models for database recovery:
- Simple
- Full
- Bulk-logged
Simple
The Simple recovery model is a basic model for data recovery. It does not back up the transaction log so you can only recover (restore) to the point of the last complete or differential backup, thus a potential loss of data. In this model, once the transaction is complete and the data pages have been written to the data file (via CHECKPOINT), the space in the log file used by those transactions is now available and can be used by new, incoming transactions. This has the advantage of keeping the transaction log small, at the cost of not being able to do a point-in-time restore.
Selecting this recovery model is still a valid option depending on the scenario. For example, a Simple recovery model is a great option for dev and test environments because the data probably isn’t that critical and losing transactions shouldn’t be a problem.
Full
The Full recovery model encompasses all the needs for data recovery. It is, in essence, the full package. In this model, all transactions are kept in the transaction log until they have been backed up. Keeping the transactions in the transaction log allows for point-in-time recovery, meaning that you can restore the data back to a specific point. This is because you have every transaction available to restore (up to the last transaction log backup) and can “roll forward” transactions up until the point-in-time desired.
While there are benefits to this model, it can also get you in trouble. As mentioned, transactions are logged and kept, and only removed from the transaction log when you back up or truncate the log. Therefore, it is best practice to implement an appropriate strategy for backing up the transaction log.
A common scenario is a database that is in FULL recovery model being restored from production to a test or development environment where backups don’t take place. If the database recovery model is not changed to SIMPLE at that time, the transaction log will never be truncated.
Selecting this model should be used in production environments where data is critical and data loss needs to be as minimal as possible. You must use this option if you are using Always On Availability Groups.
Bulk-logged
The name of this recovery model tends to lead to a bit of confusion. The confusion comes from the name of this recovery model which leads some to believe that it logs all bulk operations, in a specific and special way. The truth is actually the opposite.
The Bulk-logged recovery model is very similar to the Full recovery model in that transactions are logged and kept. Where the Bulk-logged recovery model differs from the Full recovery model is that the Bulk-logged recovery model does not fully log some bulk operations. Meaning, any statement that creates a bulk operation, such as SELECT INTO or BULK INSERT are minimally logged, keeping your transaction log small.
If your processes consist of a lot of bulk operations, you want to take a good look at using this recovery model. When no bulk operations are being run, the Bulk-logged recovery model operates just like the Full recovery model. This means, however, that the transaction log continues to grow until you back it up or truncate it.
From a data recovery point of view, this recovery model still provides point-in-time recovery as long as the backup of your log does not include a bulk operation. So you need to make sure that a Full or Differential backup takes place as soon as possible after the bulk-logged operation.
SQL Server Backup Types
Now let’s talk about backups. With our understanding of how recovery models work, the next step is to understand the different types of SQL Server backups. In the simplest form, there are three backup types:
- Full
- Differential
- Transaction Log

There are, of course, other backup options, but then we are getting into files and Filegroups, and that is a bit different. We’ll save that for a future post. For now, we’ll stick to the fundamental backup types listed above and discuss them in more detail.
Full
A Full back up is the most common type of backup. When backing up a database and setting the backup type to Full, SQL Server will back up the entire database, along with part of the transaction log, to allow for a full recovery. With a Full backup, all the contents of the database are contained in a single backup file, typically with a .bak extension.
Full backups are an easy way to copy a database from one server to another. However, as a database continues to grow in size, the time it takes to back up the database requires more time as well as taking up additional storage space. Best practice states that Full backups should be complimented with Differential and Transaction log backups to not only speed up the backup process and take up less disk space, but to also help ensure point-in-time recovery.
Differential
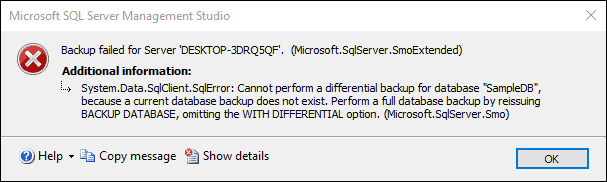
Differential backups contain only the data that has changed since the last full backup. In fact, if you try and perform a Differential backup without first taking a Full back, SQL Server will tell you it can’t do that, and that you first need to do a Full backup.
So, how do differential backups work? Let’s first back the bus up and talk about “extents”. An extent is 64K of data, comprised of eight 8KB pages. Each extent has a flag, letting SQL Server know when data has been changed on one of its pages. When data changes within an extent, the flag is turned on. When a differential backup is taken, only the data for those extents with the flag turned on are included in the backup.
To be clear, a differential backup contains the data that has changed since the last Full backup. Therefore, if you take a Full backup, then take a differential an hour later, followed by another differential an hour after that, both differential backups will contain the changes since the last Full backup. If the database needs to be restored, you first restore the Full backup, followed by the most recent differential backup.
Transaction Log
A transaction log backup provides the ability to back up the active portion of the transaction log. Backing up the transaction log is the main reason a point-in-time restore is possible. When backing up the transaction log, the backup contains all the transactions since the last Full or Differential backup occurred. Once the backup of the transaction log is completed, the space in the transaction log is freed up and available for other transactions.
As discussed earlier, the transaction log can only be backed up if the recovery model is set to Full or Bulk-logged.
A couple of acronyms that you will hear, if you haven’t already, are RPO and RTO. RPO is Recovery Point Objective, and in simple terms determines how much data loss is acceptable, and based on this value it will determine the frequency at which backups are taken using Full, Differential, and Transaction log backups. RTO is Recovery Time Objective, and signifies how much downtime is acceptable (how much time it will take to recover). Maybe a topic for another blog post.
Log Sequence Numbers
With the foundation of recovery models and backup types in place, let’s take this up a level and discuss Log Sequence Numbers (LSN’s) and log chains and how they apply to SQL Server backups and restores. This is definitely a topic you will see a subsequent blog post about.
You can think of the transaction log as a string of log records. As SQL Server writes transactions to the log, they are written sequentially as a log record. Each record in the log is given, and identified by, a log sequence number, or LSN. As records are written to the log, the record is written to the logical end of the log, and the LSN is higher than the record that preceded it.
Log Chain
A good SQL Server backup strategy includes multiple backups of the transaction log. As each backup of the transaction log is performed, they are added and maintained in a series which forms a chain called the log chain. The log chain defines an unbroken, continuous sequence of transaction log backups. As more log backups are taken, they are added to the chain in order. All log chains begin with a Full backup.
An intact or unbroken log chain is what provides the ability to restore a database to a point in time. The keywords you should take from that sentence are “intact” and “unbroken”. SQL Server is responsible for keeping the log chains intact and works hard to make sure it stays together. But the reality is that a log chain can be broken, and more often than not it is the result of human error that breaks it. When a log chain is broken, a database restore is not possible past the point where the chain is broken.
Breaking the Log Chain
Since SQL Server 2008, there are two main ways you can break a log chain, and you should be familiar with both of them so that, well, you don’t do them. They are the following:
- Changing the recovery mode of database
- Taking a Full backup of the database
In the first scenario, switching from FULL or BULK_LOGGED recovery model to the SIMPLE recovery model (and back to FULL), will break the chain. Remember that the SIMPLE recovery model doesn’t back up the transaction log, so at a high level, going from the FULL or BULK_LOGGED recovery model to the SIMPLE model and back to the FULL sort of resets the log chain. You are telling SQL Server “we don’t need to track the log”, then “oh, yes we do”, so in essence it resets the log chain.
In the second scenario, remember that a log chain starts with a FULL backup, so doing an ad hoc FULL backup will mess up the log chain. If you find yourself doing a Full backup ad hoc, you should ask yourself why you’re doing it. Realistically you should be fine using the last Full backup that was taken as part of the backup/recovery plan (which should have been recent). In the event you do need an ad hoc backup, make sure to use the COPY_ONLY backup option as this will leave the log chain intact.
This is easy to test. Create an empty database and set the recovery model to FULL. Back up the database, then back up the transaction log. Set the recovery model to SIMPLE, then set it back to FULL. Now try and take another log backup. Good luck.
There is another way to mess up the log chain that has to do with database snapshots, but we won’t get into that. The biggest two issues are the ones listed above.
As I mentioned, understanding LSNs and the log chain is vital to implementing a successful strategy for SQL Server backups and restores. The topic definitely warrants a blog post all its own so expect to see one shortly.



{kind=link}