Working with robust, sizeable data in your development environments is an important part of testing. A critical consideration prior to testing in dev is removing personally identifiable information. Because, of course, you’re not testing code in your production environment, right? … RIGHT?
OK, now we have that out of the way, we’re going to proceed with the assumption that you’re working in some sort of development environment. That can be a specific server or even just a database on a developer’s laptop. It doesn’t matter where it is.
The main issue we see in dev environments is that people take a nice little version of their database, a few hundred rows of data per table, and develop on that. This is great for checking that your logic is correct, but not good when it comes to actually deploying the code to production. Suddenly, your nice, pretty code has to deal with millions of rows of data and grinds to a halt because you didn’t write it for big data sets. No, you wrote it for your development system, and it was fast on your machine. We see this a lot.
What to do?
The obvious fix for this is to take a copy of your production database (most people grab the last full backup) and restore onto a similarly sized server to use for testing. This way you’re testing as close as you can to the production database size. This is an excellent idea, especially if you have a team or process that can run a workload against this development machine to simulate a real workload.
If you choose to do this, you’ll often hit the problem of using real people’s personally identifiable information (PII). In certain environments (e.g. healthcare, banking), we don’t want people to have access to this customer data. We still want the data size but we have to sanitize this data before it’s safe to test with. This post walks you through the process.
Removing Personally Identifiable Information
We’re focusing on a couple different data types here — names and phone numbers. There are a lot more data types that qualify as PII, but you don’t want to read a 20 page essay. What we’ll do here is to show you the principle. You can then modify these scripts to meet your specific needs and/or data types.
Phone Numbers
We’ll start by anonymizing phone numbers. This data is much simpler to change than names, and numbers are also easier to deal with than people (hey, we’re not in this career path because we like dealing with people 😂).
OK, let’s make a temporary table with some totally real phone numbers for our testing;



IF OBJECT_ID('tempdb..#PhoneNumbers') IS NOT NULL DROP TABLE #PhoneNumbers;
CREATE TABLE #PhoneNumbers (PhoneNumbers VARCHAR(20))
INSERT INTO #PhoneNumbers
VALUES
('(111) 111 1111')
,('(222) 222 2222')
,('(333) 333 3333')
,('(444) 444 4444')
,('(555) 555 5555')
Yes, this is very simple, but it’ll work just fine for this test.
Now we’re going to want to follow whatever format our phone numbers are in. I’ve included brackets and spaces just because I’m a bit of a masochist. Adapt this for whatever format your tables use.
Right: The reason we’ve started with phone numbers is because SQL Server is pretty good at just generating numbers out of thin air. We’re going to use the CRYPT_GEN_RANDOM function to generate our random values. We’ll then convert this to an INT to give us a random string of at least 4 integer values.
SELECT CONVERT(INT,CRYPT_GEN_RANDOM(2))
Run this a bunch of times. You’ll see that it’s going to randomise numbers for us. We can do a bit of messing about and get this in the format we want;
SELECT
'(' + LEFT(CONVERT(VARCHAR,CONVERT(INT,CRYPT_GEN_RANDOM(2))),3) + ')'
+ ' '
+ LEFT(CONVERT(VARCHAR,CONVERT(INT,CRYPT_GEN_RANDOM(2))),3)
+ ' '
+ LEFT(CONVERT(VARCHAR,CONVERT(INT,CRYPT_GEN_RANDOM(2))),4)
We’ve added the brackets and spaces where we need for our format. Modify this as needed.
Now, we can use this function and update our temp table;
UPDATE #PhoneNumbers
SET PhoneNumbers = '(' + LEFT(CONVERT(VARCHAR,CONVERT(INT,CRYPT_GEN_RANDOM(2))),3) + ')'
+ ' '
+ LEFT(CONVERT(VARCHAR,CONVERT(INT,CRYPT_GEN_RANDOM(2))),3)
+ ' '
+ LEFT(CONVERT(VARCHAR,CONVERT(INT,CRYPT_GEN_RANDOM(2))),4)
The results in my test look like this;
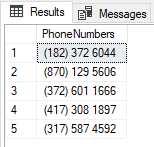
This method can be used for any data that contains only values that are integers. It won’t work for randomly generating names or other text-based data. We’ll need a different approach for these.
Generating Names
First of all, test data:
IF OBJECT_ID('tempdb..#TotallyRealNames') IS NOT NULL DROP TABLE #TotallyRealNames;
CREATE TABLE #TotallyRealNames
(
ARealPersonsName VARCHAR(20)
)
INSERT INTO #TotallyRealNames (ARealPersonsName)
VALUES
('Aaron'),('Abron'),('Acron'),('Adron'),('Aeron')
We can’t just randomly generate data (well, we could, but: the names would just be random strings of letters and wouldn’t be very nice to work with). So, instead, let’s go grab some names.
For this data here, I went to data.gov and got the top 100 baby names from a CSV list. The test data below is not the full 100 names, but you can grab a list of names from any publicly available list on the net (please check any applicable licences).
CREATE TABLE #FirstNames
(
ID INT IDENTITY(1,1)
,FirstName VARCHAR(100)
)
INSERT INTO #FirstNames (FirstName)
VALUES ('GERALDINE'),('GIA'),('GIANNA'),('GISELLE'),('GRACE'),('GUADALUPE'),('HAILEY'),('HALEY'),('HANNAH'),('HAYLEE')
We now have a list of 10 names that we can apply to our main table and replace. The issue here is that we want to apply only one name to each row of data in the main table. We’re going to have to use some sort of TOP (1) statement here, however, if we were to do a simple join like this …
UPDATE #TotallyRealNames
SET ARealPersonsName = (SELECT TOP (1) FirstName FROM #FirstNames)
… we’re going to have a problem:
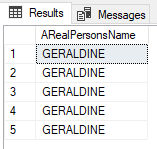
Just one name has been used to replace all of our original data. That’s no fun. To fix this, we’ll have to do some funky nonsense to get us a random selection of names in here.
Funky Nonsense;
;WITH OriginalData_CTE AS
(
SELECT
trn.ARealPersonsName
,LEFT(1 + 200 * (CAST(CRYPT_GEN_RANDOM(4) AS INT) / 4294967295.0 + 0.5),1) AS random_number
FROM #TotallyRealNames AS trn
)
,UpdateData_CTE AS
(
SELECT
od.ARealPersonsName
,NEW.FirstName
FROM
OriginalData_CTE od
OUTER APPLY
(
SELECT fn.FirstName
FROM #FirstNames AS fn
WHERE fn.ID = CAST(od.random_number AS INT)
) AS NEW
)
UPDATE UpdateData_CTE
SET ARealPersonsName = FirstNameI did warn you… OK, let’s break down what this code does.
The first CTE uses our friend CRYPT_GEN_RANDOM to generate a random int value for each row of our table. Because we only have 10 rows of data in our list of names, I have included the LEFT(,1) statement so we only return one digit. Because of this, you’re likely to see duplicates in our output data. However, if you have a sensible amount of names in your replacement list (e.g. 3 or 4 digits worth), then you won’t see these.
;WITH OriginalData_CTE AS
(
SELECT
trn.ARealPersonsName
,LEFT(1 + 200 * (CAST(CRYPT_GEN_RANDOM(4) AS INT) / 4294967295.0 + 0.5),1) AS random_number
FROM #TotallyRealNames AS trn
)The second CTE joins this random number to the ID value of the data in our replacement data:
,UpdateData_CTE AS
(
SELECT
od.ARealPersonsName
,NEW.FirstName
FROM
OriginalData_CTE od
OUTER APPLY
(
SELECT fn.FirstName
FROM #FirstNames AS fn
WHERE fn.ID = CAST(od.random_number AS INT)
) AS NEW
)This output will allow the update to happen and actually update our table. At this point, your data should look something like this;
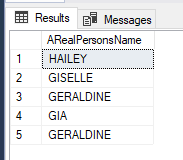
You’ll see the duplicate in the output, but that’ll happen with such small data sets.
What Have We Achieved?
At this point, you’ve got customer data that’s PII phone numbers and names replaced with sensible-looking but completely anonymous data, ready for development to safely test against.
There’s a lot more you can do with this approach if needed. The obvious next steps are to use the phone number script for fax numbers and cell numbers, but you can use the text replacement to also do full names, email addresses and anything else that uses a person’s name.
At this point, the only thing left is to go through every column of data in your database and identify exactly which columns are PII, I’ll leave that particular part of this process to you and your expert knowledge of your own environment.
Good Luck!



{kind=link}