A lot of people have heard of in-memory/memory-optimized tables in SQL Server. In our experience, however, not many people are using this feature (which first appeared in SQL Server 2014) in their production environments. This introduction will explain what in-memory tables are and how to use them effectively. This post should help guide your decision about using this feature in your production environment.
For the demos below I’m using the Stack Overflow database, you can go grab a copy here. It comes in various sizes, and a small one is perfectly acceptable for this test. We’re only going to deal with 100k rows of data. Once we have the database available and attached to a test instance of SQL Server, we have a few things to do.
Setting Up A Memory-Optimized Table
First, we’re going to create a filegroup for memory-optimized data. Then, create a file within that filegroup (the location below is for my test machine, yours will likely need to be different). Then, set memory-optimized to snapshot (which is best practice).



USE [StackOverflow];
GO
ALTER DATABASE [StackOverflow]
ADD FILEGROUP [StackOverflow_mod_fg] CONTAINS MEMORY_OPTIMIZED_DATA;
GO
ALTER DATABASE [StackOverflow]
ADD FILE (NAME = N'StackOverflow_mod', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL15.SQL2019\MSSQL\DATA\StackOverflow_mod')
TO FILEGROUP [StackOverflow_mod_fg];
GO
ALTER DATABASE [StackOverflow] SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT = ON;
GO
NEXT we’re going TO make a standard ON DISK TABLE so we can USE it FOR comparison purposes vs the in memory TABLE we’re going TO CREATE.
IF OBJECT_ID('dbo.Posts_Disk') IS NOT NULL DROP TABLE dbo.Posts_Disk;
GO
SELECT TOP (100000) -- keep this modest; raise as your RAM allows
p.Id,
p.CreationDate,
p.Score,
p.OwnerUserId,
p.PostTypeId,
p.Title
INTO dbo.Posts_Disk
FROM dbo.Posts AS p
WHERE p.PostTypeId IN (1,2) -- questions & answers, typical subset
ORDER BY p.Id;
GO
CREATE CLUSTERED INDEX CX_Posts_Disk_Id ON dbo.Posts_Disk(Id);
CREATE INDEX IX_Posts_Disk_CreationDate ON dbo.Posts_Disk(CreationDate);
GONow we’ll make an in memory version of this table.
IF OBJECT_ID('dbo.Posts_InMem') IS NOT NULL DROP TABLE dbo.Posts_InMem;
GO
CREATE TABLE dbo.Posts_InMem
(
Id INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1048576),
CreationDate DATETIME2 NOT NULL INDEX IX_InMem_CreationDate NONCLUSTERED,
Score INT NOT NULL,
OwnerUserId INT NULL,
PostTypeId INT NOT NULL,
Title NVARCHAR(250) NULL
)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA);
GO
And we’re going TO take the same DATA FROM our ON DISK TABLE and INSERT INTO our NEW in-memory TABLE;
INSERT dbo.Posts_InMem (Id, CreationDate, Score, OwnerUserId, PostTypeId, Title)
SELECT Id, CreationDate, Score, OwnerUserId, PostTypeId, Title
FROM dbo.Posts_Disk
GOLet’s do a comparison between our on disk table and our in-memory table. The first comparison we’ll do is to return one record from each table and check the statistics. I wanted an Id that’s roughly in the middle of my tables so that it would be a meaningful comparison. Id 88,011 appears on row 50,000 of my table so I’m using that in the queries below. This may be different in your version of the database.
SET STATISTICS TIME,IO ON;
SELECT * FROM dbo.Posts_Disk WHERE Id = 88011;
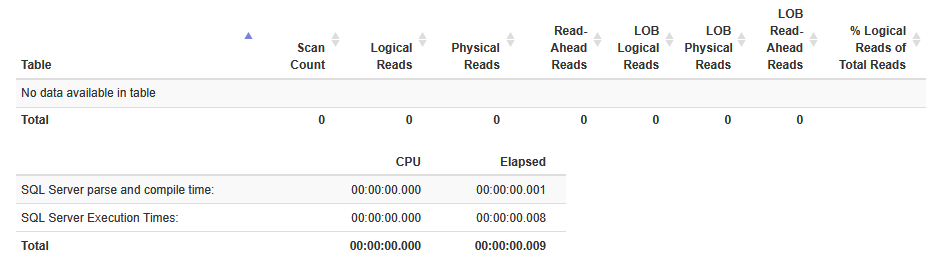
SELECT * FROM dbo.Posts_InMem WHERE Id = 88011;If we copy the statistics from the messages tab output in SSMS and paste into statisticsparser.com (to make it readable), you’ll notice we perform 3 logical page reads on the Posts_Disk table, but zero reads on Posts_InMem.
Now, let’s do a date range comparison. For the parameters used below, I have taken the values from row 30,000 and 70,000 as my two dates so we return a decent amount of the sample data.
SET STATISTICS TIME,IO ON;
DECLARE @d1 DATETIME2 = '2008-09-08 23:48:24.2570000';
DECLARE @d2 DATETIME2 = '2008-09-22 22:38:47.5570000';
SELECT COUNT(*)
FROM dbo.Posts_Disk
WHERE CreationDate >= @d1 AND CreationDate < @d2;
SELECT COUNT(*)
FROM dbo.Posts_InMem
WHERE CreationDate >= @d1 AND CreationDate < @d2;
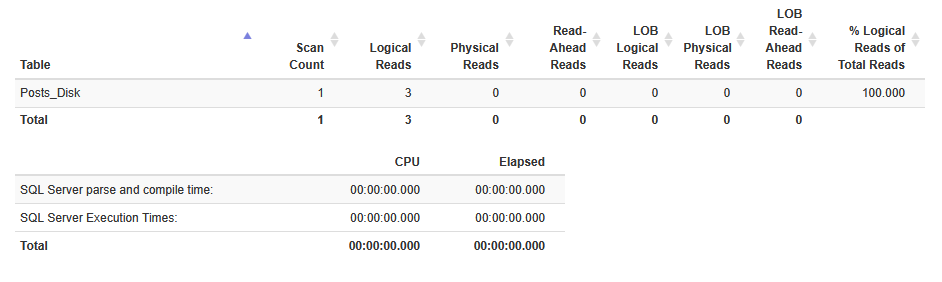
GOIf we put the stats into statisticsparser.com again, you’ll see that on the Posts_Disk table we have 96 logical reads and an execution time of 38ms.
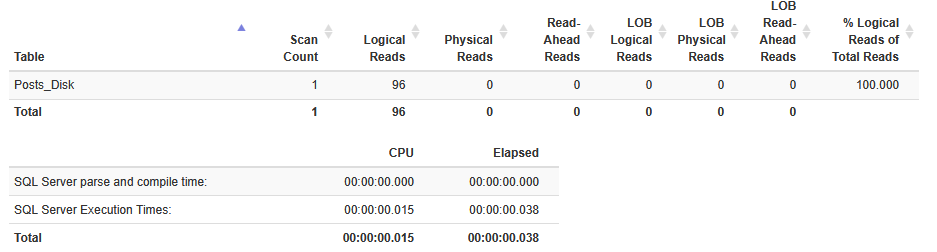
And for our in-memory table we show zero logical reads and an execution time of 9ms.
Things get interesting when we compare execution plans.
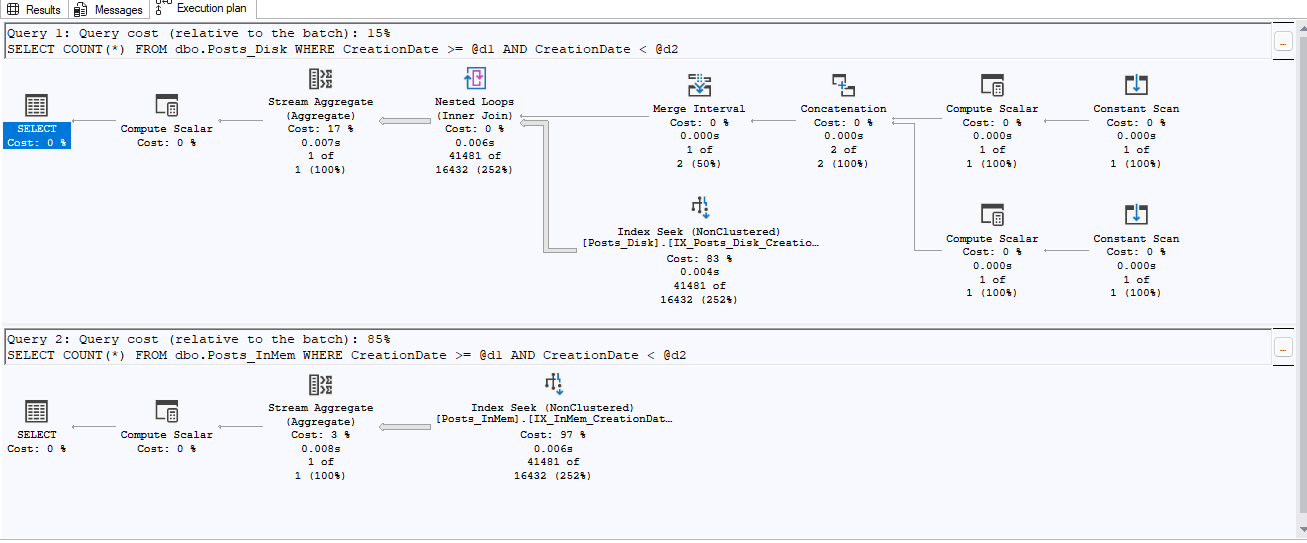
The query plan at the top is a lot more complicated. It shows the worktables that are being created behind the scenes, but it reports only 15% of the overall estimated query cost. In contrast, the query below is showing as more expensive but from the statistics we can prove that it produces its results much quicker than the on-disk table. This gives us caution when comparing execution plans as they can have bad estimates and provide misleading data.
What Have We Found?
From all this, we’ve proven that in-memory tables can perform much better than classic on-disk tables. However, that’s not saying there aren’t significant considerations to evaluate when it comes to using these tables. The list below is far from exhaustive, but rather what we consider the most restrictive or problematic points to consider.
Architectural Issues
- All data must fit into memory.
- Very large tables are impractical unless we have loads of memory to spare (spoiler: not many people have memory to spare when it comes to SQL Servers)
- Compression is not supported for in-memory tables, this gives these objects an even higher memory footprint.
Indexing
- The following index types are not supported
- Clustered Indexes
- Filtered Indexes
- Non-clustered indexes that have included columns
- You must also be very considerate of your hash index bucket sizes.
- Too few: Bad performance from long chains and collisions
- Too many: Wasted memory (buckets are allocated up front and never shrink)
- Index rebuilds and reorganize operations are not supported, only drop/create to achieve the same goal
T-SQL Limitations
- No check constraints
- No foreign key cascades
- No foreign keys referencing disk based tables from in-memory tables
- There are unsupported data types depending upon your SQL Server version
- No IDENTITY columns
- No Merge statement (not a bad thing in one DBA’s opinion, at least)
Should You Use Memory-Optimized Tables in SQL Server?
Ultimately, if you’re considering using in-memory tables, I would recommend researching the advantages and disadvantages extensively. You would be well advised to test on a large dataset (a copy of production is ideal, because you’re not testing in production, right?) to see how your specific workload would react to using in-memory tables.
Have you implemented in-memory tables and are they working well for you? We’d love to hear about your experiences, so share your story in the comments below.



{kind=link}