We’ve recently come up across a fun little bug with log shipping in contained availability groups. A cursory Google search did not bring up any useful posts for troubleshooting, so here we are. If you’re here for the bug, feel free to scroll to the bottom of this post. For the rest of you, however, let’s add a little context to this scenario before getting to the meat of the situation.
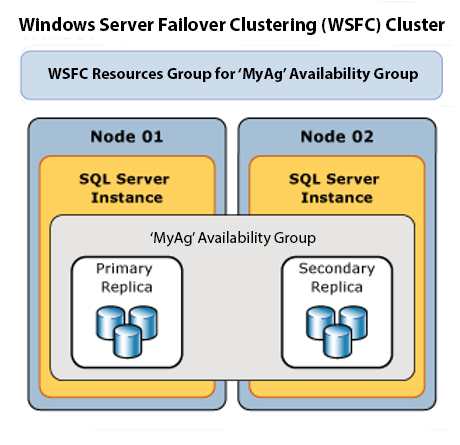
What’s an Availability Group?
In short, Availability Groups (AGs) are a SQL Server feature that enables you to connect multiple servers (at least two, limits depend upon your edition) together so they can share databases. One server runs as the Primary node and the others act as secondary nodes. In this example we’re going to assume we’re in a two-node AG with one Primary Node and one Secondary Node. We’re also going to assume we have a synchronous AG here.
In this setup, the nodes share the databases and sync with each other. The primary server holds the primary copy of the database and the secondary server holds a read only copy of the same database. The idea is that if we lose the primary node for whatever reason, the AG will fail over and make the other node the primary node. This removes any downtime concerns and allows for things like patching to take place without making the database inaccessible while this happens.
The main issue people have is that while databases are shared between the two servers, we (as DBAs) have to keep all non-databases objects synchronized across both nodes — things like user logins, SQL Agent jobs and server level settings. We can do this with tools like the dbatools powershell modules. But, Microsoft decided that they wanted to make this process slightly easier for us.
How is a contained Availability Group different?
Contained AGs add a third server category, the Listener. This is what users will usually see and connect to; they won’t connect to the nodes separately. This listener also contains all of the server level objects, so you no longer have to do things like sync your agent jobs and logins across your nodes manually.
There are some things to consider. Such as, agent jobs will only run on the primary node at all times. If you want them to run on the secondary then you will have to install it on the nodes directly and avoid the contained AG.
The Bug: Transaction Log Shipping
The reason for this blog post is the bug that was mentioned at the beginning. In this scenario, we have a customer with a contained AG that has log shipping involved.
To quickly summarize: log shipping is the act of taking transaction log backups on a server and restoring them elsewhere to make a read-only copy of the original database. In this scenario, the logs are shipped to a server that processes reporting workloads so that this workload does not happen on the main production servers.
Once we set up transaction log shipping in place, we will have three Agent jobs:
- LSBackup_DatabaseName: This will happen on the primary node (or the listener in the case of a contained AG) and performs the transaction log backup.
- LSCopy_DatabaseName: This is installed on the recipient of the log shipped data; in this scenario, the reporting server. This finds all of the log backups that have happened within LSBackup and copies them over to the target server.
- LSRestore_DatabaseName: This uses the local log backups and restores them to the local copy of the database.
Contained AGs absolutely support transaction log shipping. It works much better as you don’t have to manage the primary/secondary server relationship at all. However, we wouldn’t all be here if it was all butterflies and roses, would we?
When you set up log shipping using the GUI you will need several pieces of information to get to the right place. This includes things like backup paths for shared folders, server names, etc. Our specific bug is all about the server names.
The problem occurred when, for patching, a planned failover of the AG happened. This caused the LSBackup job to begin failing. This meant that there were no files to copy over, and therefore the reporting database began falling behind with data. With no backups, it also caused the transaction log to increase in size.
The specific error we began getting was this (GUID is a placeholder for an actual GUID):
Error: Could not retrieve backup settings for primary ID ‘GUID’
Which is odd in a contained AG, as technically the primary node never changes (it’s always the listener).
We then see, upon the built-in retry logic, the following error:
Error: Failed to connect to server “SECONDARY NODE”
Which it shouldn’t be trying to do at all.
I scripted out the log shipping configuration and the only server names involved were the listener and the reporting server. I didn’t see any reference to a specific node, so I went digging.
By looking at the LSBackup agent job, we could see that, for some reason, it had been generated with the server name of the primary node at the point of the log shipping being set up:
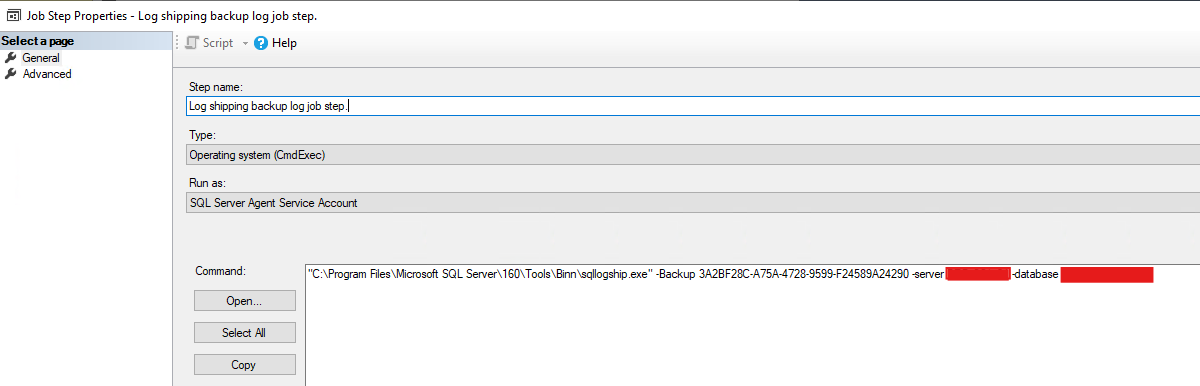
This was the source of the issue. It was trying to read backup information from a secondary database, which it was unable to do. It was therefore failing on log backups. I have no idea why it would have chosen this server. This is now something we’re going to build into all of our checks moving forward.
Fixing the Bug
The fix is simple: Change this job manually to look at the listener and execute the agent job. It will likely take a lot longer than it usually would as it’s backing up a lot more data than normal. However, once complete, the LSCopy and LSRestore jobs will do their job and get the target database up to date.
Hopefully this helps anybody in a similar situation, feel free to reach out if you have any specific questions at all around any of this. I’d be more than happy to have a chat about log shipping in contained availability groups.



{kind=link}